# Business Logic Protocol 2
# How is BLS Protocol 2 different from (the now deprecated) Protocol 1?
BLS protocol 2 aims to improve on Clinc's existing cutting edge technology and make it easier to wield. It is optimized for network latency and reduction of business logic complexity, while allowing more control of slot resolution.
# Better Slot Resolution
Each slot now has a status associated with it. Since we know that a slot resolution has many steps, we have replaced the binary resolved flag with a flexible status variable, affording the BLS more visibility over slot resolution. There is also a new, simpler interface to the slot mapping api, which can be used for simple mapping tasks, and be extended to far more challenging situations.
Here is what an example slot value could look like:
"slots": {
"_ACCT_INFO_": {
"type": "string",
"values": [
{
"status": "CONFIRMED",
"tokens": "checking",
"available_balance": 223355,
"balance": 223355,
"bankname": "My Fav Bank",
"currency": "usd",
"last_four": "9876"
}
]
},
}
# New Network Call Paradigm
The new Business logic architecture eliminates the need for external Clinc calls for slot mapping. Instead of calling Clinc directly with an API as was the case with previous versions, the BLS simply needs to return a list of candidates to Clinc as part of the response, and Clinc will call the BLS with the mapping result. This ensures that the BLS makes minimal external calls to the Clinc stack, and reduces overall processing time.
This reduces the BLS complexity and frees it to focus on processing user-specific code, as it is not bogged down with slot resolution and can reliably offload that messy work to Clinc.
The workflow for the protocol is as follows:
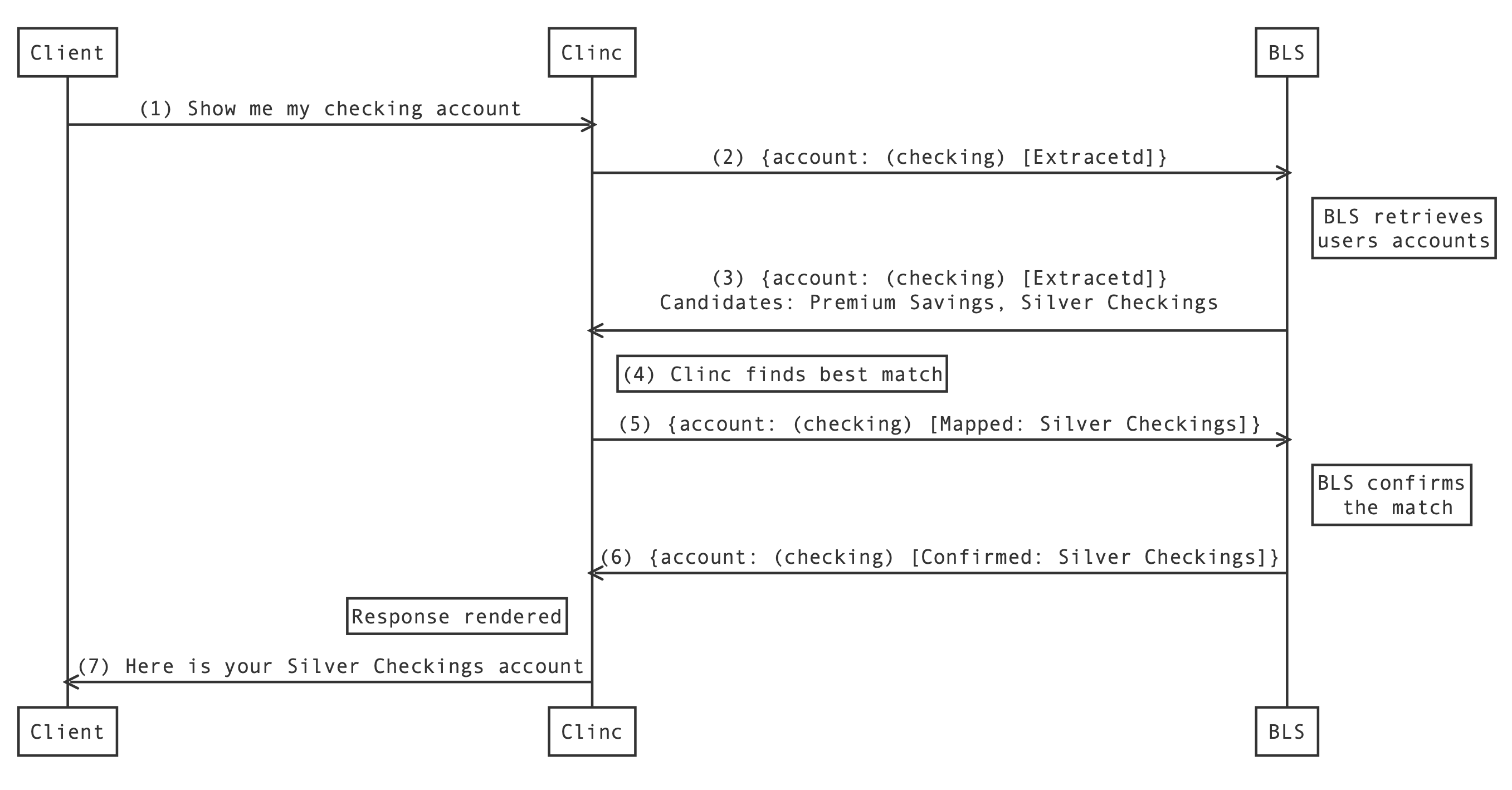
- Client makes a request to the Clinc platform with the user's query.
- After classification and SVP, Clinc sends the data to the BLS. New slots that are found will be marked as Extracted.
- BLS retrieves any necessary information for processing, and provides Clinc with a list of candidates that could be used for mapping the slots (see Mapping specifications). The BLS returns these candidates in the response payload back to Clinc.
- Clinc will find the best match based on the slot value and the list of candidates that the BLS provided.
- Clinc sends a second request to the BLS with the same query but updated slots. The status of the slot will depend on the result of mapping the candidates. (See Slot Status Codes)
- BLS will validate any mapped slots into confirmed slots, and return it to Clinc for response generation
- Clinc will use the slots and data provided by the BLS to create the response and send it to the client.
Note that Clinc is doing the heavy lifting here and the BLS only has to retrieve the user data and provide candidates for mapping. It's also important to note that the BLS will be called a minimum of two times if a slot needs to be resolved. However, the resolution of all the slots happens at once, so as your list of slots grow, the processing performance is not hindered!
# Business Logic HTTP Request Headers
Any custom HTTP headers sent in the POST request to the /query end point will be forwarded in HTTP headers of the business logic POST request. Because HTTP headers are not case sensitive, they will be converted from their original form to all upper case in the business logic POST request. For example, if your POST request to the /query end point has the following headers:
Content-Type:application/json
Authorization:Bearer utbDHMuTP1y0N20qpkcvR65DZRlHvV
test-key:test value
test-key2:test value 2
You can expect to see the following headers in the business logic POST request (among others):
AUTHORIZATION:Bearer utbDHMuTP1y0N20qpkcvR65DZRlHvV
TEST-KEY:test value
TEST-KEY2:test value 2
# The Request Body
On every request, the platform will check whether the current competency is enabled with business logic it will send a request to the business logic endpoint with a request similar to the following:
POST /<BL-URL> HTTP/1.1
{
"qid": "6d090a7e-ba91-4b49-b9d5-441f179ccbbe",
"lat": 42.2730207,
"lon": -83.7517747,
"state": "transfer_start",
"dialog": "lore36ho5l4pi9mh2avwgqmu5mv6rpxz/98FJ",
"device": "web",
"query": "I want to transfer $400 from my checking account to my savings account.",
"time_offset": 300,
"sentiment": 0,
"intent_probability": 0.9663874169751958,
"session_id": "d4771d9b93c9430981ed4c7035b11ab5",
"slots": {
"_ACCOUNT_FROM_": {
"type": "string",
"values": [
{
"tokens": "my checking account",
"status": "EXTRACTED"
}
]
},
"_ACCOUNT_TO_": {
"type": "string",
"values": [
{
"tokens": "my savings account",
"status": "EXTRACTED"
}
]
},
"_TRANSFER_AMOUNT_": {
"type": "string",
"values": [
{
"tokens": "$400",
"status": "EXTRACTED"
}
]
}
}
# Payload Keys
| Keys | Explanation |
|---|---|
qid | Unique identifier for the query |
lat | Latitude of the query origin |
lon | Longitude of the query origin |
state | Current state after classification and variable transitions have been completed. |
dialog | Unique identifier representing the current conversation state. It may be added into a future query as a field of the same name to maintain state. |
device | Device of the query origin |
query | Query that the platform has processed |
time_offset | Time zone offset from UTC |
sentiment | Sentiment determined for this query. The possible values for this are: -1 (negative), 0 (neutral), 1 (positive). |
intent_probability | A confidence score associated with the classification prediction. This is a decimal number between 0 and 1. |
session_id | ID for the session this user's conversation was made. |
# The slot dictionary
| Keys | Explanation |
|---|---|
type | The type of the data in the slot. The possible values string, date, number, or money. |
values | A list of dictionaries, one for each instance of the slot extracted form the user query. |
# The values array of dictionaries
| Keys | Explanation |
|---|---|
tokens | Original tokens that were extracted from the user query. |
status | There are six possible values that can be represented here: EXTRACTED, MAPPED, FAILED_MAPPING, CONFIRMED, REJECTED, DELETED. See Slot status Codes for more information. |
# Slot Status Codes
Each slot has an attached status code. The status code is a way for the Clinc platform and the BLS to communicate when a slot needs to be processed and if the response is ready to be generated.
The status of a slot can be set by both Clinc and the BLS, but there are certain status codes that are reserved for Clinc, and others reserved for the BLS. See table below.
| Status | Resolved | Will Recall BLS | Available in Response Generation | Sent By |
|---|---|---|---|---|
| EXTRACTED | No | No | Yes | Both |
| MAPPED | No | Yes | Yes | Both |
| CONFIRMED | Yes | No | Yes | Both |
| FAILED_MAPPING | No | Yes | Yes | Clinc |
| REJECTED | Yes | No | Only current turn | BLS |
| DELETED | Yes | No | No | BLS |
# Clinc Status Codes
Here is the list of status codes that you can expect from Clinc:
EXTRACTED: Clinc has found a new slot.
MAPPED: Clinc found a valid mapping to the slot.
CONFIRMED: This slot has been confirmed by the BLS, and has been kept in context.
FAILED_MAPPING: Clinc attempted to map this slot but failed to find a match from the candidates. The BLS is expected to either delete this slot or provide alternative candidates and set the status to EXTRACTED to retry mapping.
# BLS Status Codes
The BLS can return each slot with one of the following statuses, and Clinc will process them accordingly.
EXTRACTED: BLS has seen this slot. If no candidates are provided by the BLS, Clinc will call the BLS again. For more information on this, see Recall Policy.
MAPPED: BLS has mapped this slot to a value, but has not resolved it yet. Clinc stores this slot in the context and call the BLS again with this value.
CONFIRMED: BLS has mapped and resolved this slot. Clinc will not call the BLS for this value, but it will be included in future calls if the BLS is called for other slots.
REJECTED: BLS has rejected this slot. Clinc will only store it the context for one more turn. Clinc will not call the BLS for this value again.
DELETED: BLS has deleted this slot. Clinc will delete this slot, and it will not be in the next conversational turn. Clinc will not call the BLS for this value again.
# Recall Policy
A key feature of protocol 2 is being able to recall the BLS after slot mapping occurs on the Clinc platform. With great power comes great responsibility, and the same is true for this feature. There are a few cases where you will need to pay extra attention to ensure the recall mechanism works in your favor.
First, let’s define a recall. A recall is when the Clinc platform makes a subsequent network call to the BLS after the initial one, due to a lack of slot mapping confidence or definition. This means that a recall will always happen when there are slots that need to be resolved. A slot is considered resolved if its state is CONFIRMED, REJECTED, or DELETED. Any other status will mark the slot as unresolved, triggering the recall policy. An example of how this works is shown in New Network Call Paradigm.
# Recall Limit
The recall policy creates a possibility of an infinite loop between the platform and the BLS. This is why there is a recall limit of 10 on any conversational turn. This means a maximum of 10 network calls will be made to the BLS before deleting a slot from the context.
# The Response Body
The business logic can manipulate the state and slots properties within the request body, and everything else is read-only. After the business logic completes the changes to the payload body, it sends it back to the Clinc AI Platform as the response body.
At a high level, the response of your POST handler is the request body along with any additions/mutations to slots or state. Upon a successful response from a business logic server, the new set of variables will be directly passed into the user's response templates, allowing them to customize their responses with the new slots introduced in the business logic.
HTTP/1.1 200 OK
{
"lat": 42.2730207,
"qid": "6d090a7e-ba91-4b49-b9d5-441f179ccbbe",
"lon": -83.7517747,
"dialog": "lore36ho5l4pi9mh2avwgqmu5mv6rpxz/98FJ",
"device": "web",
"query": "I want to transfer $400 from my checking account to my savings account.",
"time_offset": 300,
"sentiment": 0,
"intent_probability": 0.9663874169751958,
"session_id": "d4771d9b93c9430981ed4c7035b11ab5",
"state": "transfer_confirm",
"slots": {
"_ACCOUNT_FROM_": {
"type": "string",
"values": [
{
"tokens": "my checking account",
"status": "CONFIRMED"
"value": "College Checking Account",
"account_id": "353675",
"balance": "5824.24",
"currency": "USD"
}
]
},
"_ACCOUNT_TO_": {
"type": "string",
"values": [
{
"tokens": "my savings account",
"status": "CONFIRMED",
"value": "savings account",
"account_id": "7725485",
"balance": "332.21",
"currency": "USD"
}
]
},
"_TRANSFER_AMOUNT_": {
"type": "money",
"values": [
{
"tokens": "$400",
"status": "CONFIRMED",
"value": "400.00",
"currency": "USD"
}
]
}
}
}
# Setting status statuses in slot responses
If you compare the request body and response body side by side you will discover that the state key has changed from transfer_start to transfer_confirm, status value has changed from EXTRACTED to CONFIRMED with the value passing from the business logic back to the platform.
Note: Besides tokens, resolved and value, arbitrary key-value pairs can be added to the dictionary by the business logic, to pass more information to the platform. In the example shown, currency was set by the Business Logic.
| Keys | Explanation |
|---|---|
state | The state that the query is landing on. |
status: CONFIRMED | If the slot is valid and you want to keep it, set status: CONFIRMED. |
status: REJECTED | If an identified slot doesn't quite match, or is incorrect, a status: REJECTED will remove the extracted slot. |
status: DELETED | Similar to status: REJECTED, this will delete the slot but will not include it in the final response to the user. |
status: EXTRACTED | If there are multiple possible values, and you would like the AI to try to determine which is the best match, you can send a status: EXTRACTED, along with a list of possible values inside of a candidates key, along with a slot mapping configuration in a mappings key, in the top level of the dictionary for that slot (both of these keys are explained in Slot mapping with status: EXTRACTED below). This will perform a slot mapping on that slot to determine the best possible match in candidates for the value of the slot. |
value | This is the new value you would like to pass from the business logic back to the platform. |
If the slot is valid and you want to keep it, set "status": "CONFIRMED", and return it to Clinc:
"slots": {
"_ACCOUNT_FROM_": {
"type": "string",
"values": [
{
"tokens": "John's checking account",
"status": "CONFIRMED",
"value": "College Checking Account",
"account_id": "353675",
"balance": "5824.24",
"currency": "USD"
}
]
}
}
If an identified slot doesn't quite match, or is incorrect, a "status": "REJECTED" will remove the extracted slot:
"slots": {
"_ACCOUNT_TO_": {
"type": "string",
"values": [
{
"tokens": "credit card",
"status": "REJECTED"
}
]
}
}
# Dynamic slot mapping with status: EXTRACTED
If there are multiple possible values, and you would like the AI to try to determine which is the best match, you can send a "status": "EXTRACTED", along with a list of possible values inside of a candidates key and a mappings key in the top level of the dictionary for that slot. This will perform a slot mapping on that slot to determine the best possible match in candidates for the value of the slot.
Dynamic slot mapping with BLS 2 supports a subset of the slot mappers available on the platform. These are the currently supported slot mappers through BLS 2:
- Fuzzy Matching (fuzzy)
- Phrase Embedding (phrase_embedder)
- Casading Priority (cascading_priority)
- Regex (regex)
- Exact (exact)
# Simple Mapping
The simplest and default mapping is Fuzzy matching. It can be used by simply passing a list of candidates and search_fields. The candidates field should contain the list of objects from which you are attempting to find your match. The search_fields should be a list of strings that are associated with the keys of the candidate objects that you would like to evaluate the slot mapping on. Each candidate object is required to have a value property.
For example, if you had a list of car objects and you would like to map against their colors, the candidates and search_field might look like this:
{
"search_fields": ["color"],
"candidates": [
{
"value": "red",
"name": "car 1",
"color": "red",
"make": "Honda",
"year": 2001
},
{
"value": "red",
"name": "car 2",
"color": "blue",
"make": "GM",
"year": 2002
},
{
"value": "red",
"name": "car 3",
"color": "black",
"make": "BMW",
"year": 2003
}
]
}
# Custom Mapping
To use the more advanced slot mappers, you can pass a mappings list that contains a list of non-empty slot mappers that will be run in consecutive order. In most cases, you will want to only pass a list of one slot mapper config. If you pass multiple mappers, the mapping algorithm will exit when the first match is found, without attempting other mappings. At a minimum, each slot mapper configuration must include a type string field indicating the slot mapper and a values list field indicating the values to map against. With customer mappings, you're required to pass a candidates list but not required to pass a search_fields list. Each candidate must have a matching value to its counterpart in the mappings.values list.
Below is a demonstration of a custom Phrase Embedding mapping on the previous example.
{
"mappings": [
{
"type": "phrase_embedder",
"threshold": 0.6,
"values": {
"red": ["red"],
"blue": ["blue"],
"black": ["black"]
}
}
],
"candidates": [
{
"value": "red",
"name": "car 1",
"color": "red",
"make": "Honda",
"year": 2001
},
{
"value": "blue",
"name": "car 2",
"color": "blue",
"make": "GM",
"year": 2002
},
{
"value": "black",
"name": "car 3",
"color": "black",
"make": "BMW",
"year": 2003
}
]
}
Each slot mapper accepts a set of configuration parameters.
# Phrase Embedding
- type: must be
phrase_embedder - threshold: a float between 0.0 < x < 1.0
- values: an object of keys -> synonyms. Each key is a list of synonyms (strings) that should map to that key. Each key must have a corresponding value in the candidates list. See Values list in mappings for more detail.
Example:
{
"type": "phrase_embedder",
"threshold": 0.6,
"values": {
"red": ["red"],
"blue": ["blue"],
"black": ["black"]
}
}
# Fuzzy Matching
- type: must be
fuzzy - algorithm: must be one of
simple_ratio,token_set_ratio,token_sort_ratio, orpartial_ratio, corresponding to the ratio algorithm used in this library (opens new window). - threshold: a float between 0.0 < x < 1.0
- values: an object of keys -> synonyms. Each key is a list of synonyms (strings) that should map to that key. Each key must have a corresponding value in the candidates list. See Values list in mappings for more detail.
Example:
{
"type": "fuzzy",
"algorithm": "partial_ratio",
"threshold": 0.6,
"values": {
"red": ["red"],
"blue": ["blue"],
"black": ["black"]
}
}
# Cascading Priority
- type: must be
cascading_priority - blocks: a list of block objects. Each block object must have the following attributes:
- name: the name of the block, to be later referenced by
cascadeobjects. - search_fields: a list of strings denoting the fields to use for mapping in the values list.
- values: a list of objects. Each object must contain the fields in
search_fields. The first object to match according to the cascade will be returned. The same rules for Values list in mappings apply here.
- name: the name of the block, to be later referenced by
- cascade: a list of objects. Each object is a mapping config of either
phrase_embedderorfuzzymapper. Each object must containn the following properties:- type: must be
phrase_embedderorfuzzy. - threshold: a float between 0.0 < x < 1.0.
- block: the name of the block to perform this specific mapping on. Only the objects in the referenced block will be considered for mapping.
- algorithm (fuzzy): must be one of
simple_ratio,token_set_ratio,token_sort_ratio, orpartial_ratio, corresponding to the ratio algorithm used in this library (opens new window).
- type: must be
- values: an object of keys -> synonyms. Each key is a list of synonyms (strings) that should map to that key. Each key must have a corresponding value in the candidates list. See Values list in mappings for more detail.
Example
{
"type": "cascading_priority",
"blocks": [
{
"name": "color_block",
"search_fields": ["color"],
"values": [
{
"value": "red",
"name": "car 1",
"color": "red",
"make": "Honda",
"year": 2001
},
{
"value": "blue",
"name": "car 2",
"color": "blue",
"make": "GM",
"year": 2002
},
{
"value": "black",
"name": "car 3",
"color": "black",
"make": "BMW",
"year": 2003
}
]
}
],
"cascade": [
{
"type": "fuzzy",
"algorithm": "partial_ratio",
"threshold": 0.6,
"block": "color_block"
}
]
}
# Exact
- type: must be
exact. - values: an object of keys -> synonyms. Each value is the exact string you want the slot to match against. Each key must have a corresponding value in the candidates list.
This example will match only slots that are exactly red, black, or blue.
{
"mappings": [
{
"type": "exact",
"values": {
"red": ["red"],
"blue": ["blue"],
"black": ["black"]
}
}
]
}
# Regex
- type: must be
regex. - values: an object of keys -> synonyms. Each value is the regex string you want the slot to match against. Each key must have a corresponding value in the candidates list.
This example will match slots that begin with r, end with d, and have zero or grater number of es in between them, like red, reeed, or rd. It will also match blue and black.
{
"mappings": [
{
"type": "regex",
"values": {
"red": "re*d",
"blue": "blue",
"black": "black"
}
}
]
}
# Contextual Phrase Embedder
type: must becontextual_phrase_embedderthreshold: a float between 0.0 < x < 1.0values: Similar to that in the phrase embedder, it is a json object. Thekeymust be present in thevaluesub-field of thecandidatelist . The value for each key is a list of strings, also called secondary clusters. Each item in the secondary cluster should be a phrase or sentence that is matched with the utterance, so that if the similarity score is beyond thethresholdthen the correspondingkeyis considered a candidate for mapping. See Values list in mappings for more detail.- More about the secondary clusters: Contextual Phrase Embedder (CPE) works best with phrases or sentences in secondary clusters. Within each secondary cluster item, certain keywords can be highlighted within square brackets
[], so that the CPE will focus on these keywords while generating the embedding. In the example of secondary clusters below, notice how the keywordsavingis enclosed withinShow saving account. Keywords can only be continuous grouping of words so that there is only one pair of square brackets within each secondary cluster item. compare_utterance: It is a boolean flag defaulted toFalse. By enabling it, the entire utterance is compared rather than just the slot value. It may be intuitive to enable it for better context, but the CPE does not encode words in isolation. In other words, the wordcheckingin the following texts:Show my checking balanceandI am checking my savings balancewill have different representations as the context is different in each. As such, we recommend disabling it - doing so will especially help with long utterances.return_score: It is a boolean flag, defaulted toFalse. IfTrue, then a json object called will be returned, with the key as each item of each secondary cluster and the value as the similarity score with the slot value in the utterance. It is a powerful feature that can be leveraged by a developer to curate data in the secondary clusters, based on the similarity scores of various combinations of secondary cluster values used.
Sample mappings object:
{
"mappings": [
{
"type": "contextual_phrase_embedder",
"threshold": 0.6,
"values": {
"saving": ["Show [saving] account"],
"checking": [
"Show [checking account]",
"Let me see [checking account]",
],
"IRA": ["Show IRA account"],
},
"compare_utterance": True,
"return_score": True,
}
]
}
Sample response with the return_score flag turned on - see the similarity score of each secondary cluster in the scores object
{
"slot_values": {
"_ACCOUNT_": {
"type": "string",
"values": [
{
"account_id": "7725485",
"balance": "332.21",
"currency": "USD",
"scores": {
"Let me see checking account": 0.7687798738479614,
"Show [IRA] account": 0.4969649910926819,
"Show [checking account]": 0.8478943109512329,
"Show [saving] account": 0.5753939747810364
},
"status": "CONFIRMED",
"tokens": "checking",
"value": "checking"
}
]
}
}
}
The BLS can also add new slots within the slots dictionary for the CPE to map them. Since the CPE needs the context of the slot word, BLS also needs to add the query and highlight the slot word within square brackets. Given below is an example of how BLS can add one or more slots in a query and have CPE map them according to the mappings object. In the example, the query is I’m just checking; show my transactions for hawaii for my checking account with my card nicknamed hawaii and the three slots are checking , hawaii , and hawaii , each highlighted within square brackets within the query separately three times.
{
"slots": {
"_TRXN_SPND_HIST_FILTER_": {
"type": "string",
"values": [{"status": "EXTRACTED", "tokens": "checking",
"query": "I’m just checking; show my transactions for hawaii for my [checking] account with my card nicknamed hawaii"},
{"status": "EXTRACTED", "tokens": "hawaii",
"query": "I’m just checking; show my transactions for [hawaii] for my checking account with my card nicknamed hawaii"},
{"status": "EXTRACTED", "tokens": "hawaii",
"query": "I’m just checking; show my transactions for hawaii for my checking account with my card nicknamed [hawaii]"}],
"candidates": candidates,
"mappings": mappings,
},
},
}
# Values List In Mappings
The values list in a slot mapper config represent the objects that the mapper can look to map against. This list is inherently linked to the candidates list by the value property of every object in the list. A mapper will operate on the objects in mappings.values list, and when a match is found according to the mapper config, the matched object will be looked up in the candidates list.
This means that the mappings.values list can be a slimmed down version of the candidates list with only the important fields that are needed for mapping. In most cases, this will mean that mappings.values will be list of objects only containing the value property.
# Requirements
- The values property must be a list of objects
- Each object in the list must have a unique
valueproperty of type string.
Last updated: 09/01/2023