# Slot & Slot-Value Pairing
# What
# What is a slot?
A slot is a key piece of information whose value you want to extract from the user utterances to return meaningful responses or drive logic. It is used to select information which has been requested or to complete an action that requires this information. For example, in order for an AI to be able to help you get your bank account balance, the key information i.e. slot you would need to provide is your account type: checking, savings etc.
# What is slot-value pairing (SVP)?
Slot-value pairing is another AI engine that the Clinc AI Platform uses to train the AI to be able to understand natural human discourse. The Slot-Value Pairing (SVP) engine parses through every word in the input query and extracts words and/or phrases that belong to slots specified by you when creating the competency. This happens post-classification based on the slots relevant to the new state.
The slot values extracted then get passed to your Business Logic server to get validated, then you can use that information to process the user’s request. Say for example a user would like to know their account balance. After the AI extracts their account type, it will then talk to the bank's API and ask for the user’s checking account balance. Then the AI passes that information back to the end user as either a visual or speech response, and in some cases both.
Slot data is used to train the SVP model to identify what data should be extracted, where this data usually appears in the sentence, and what shape the words usually take.

With the classification data collected, you would usually also label the slots in them (as shown in the image above). "Unlabeled" is also a label which trains the AI engine to be able to extract slot more accurately.
# How
How to use Auto Replace and Auto Label?
How to use the slot data distribution tool?
How to utilize slot-value pairing?
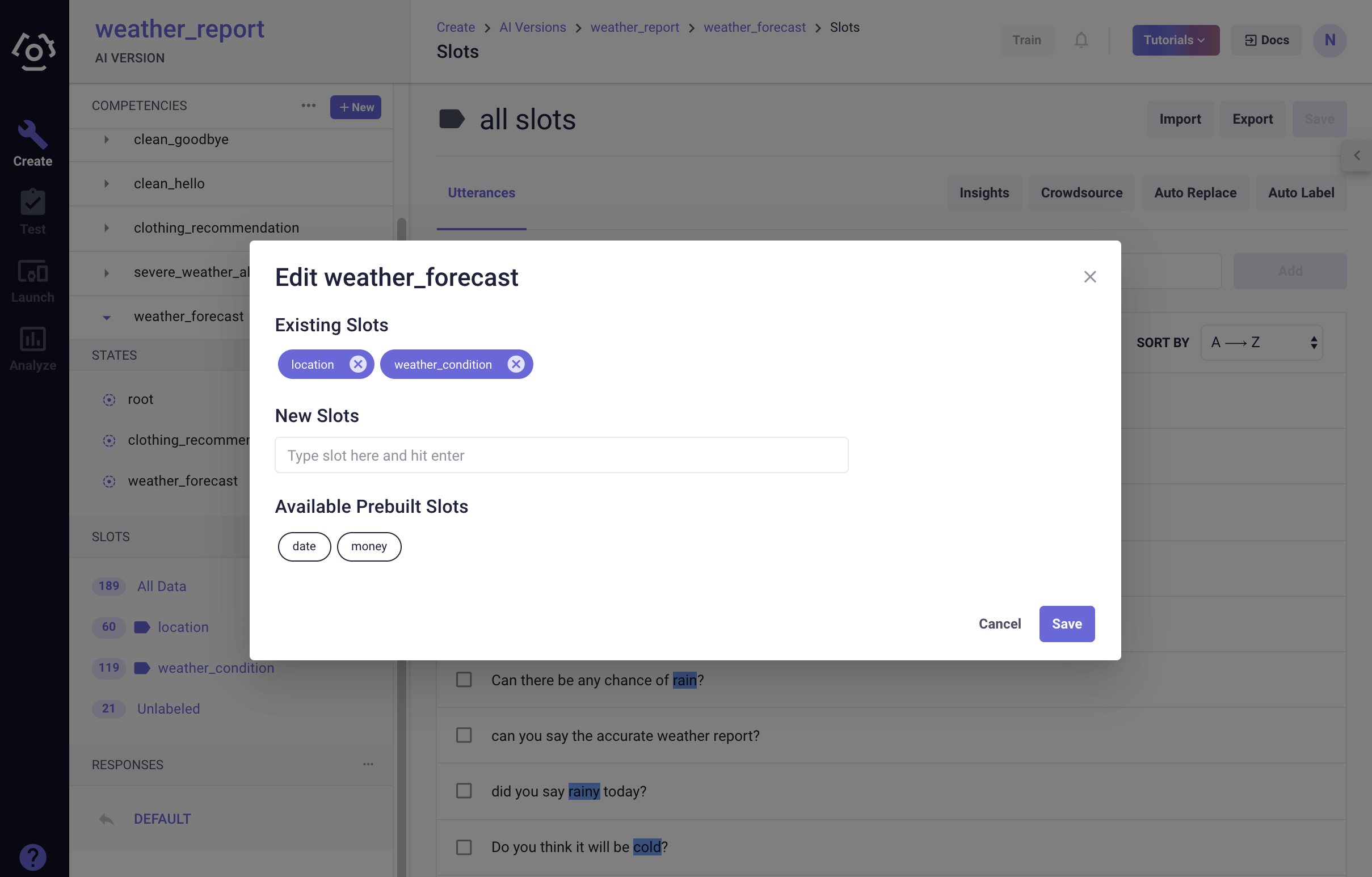
# How to add/remove a slot?
To add/remove a slot post creation of the competency:
In the overflow menu
 next to the competency name in the competency sidebar, select edit.
next to the competency name in the competency sidebar, select edit.In the modal popped up, you can delete existing slot or add new slots. Press enter after each entry.
# How to collect slot data?
Generally in the Clinc AI Platform, there are three ways to collect slot data:
- Manual Labeling
- Import
- Crowdsource
# Manual Labeling
From your AI workspace, select the competency/state/transition, click on the slot name that you would like to add data to.
On the slot data page, type in utterances in the Add a new utterance field one at a time and click Add. Or you can also select classification data and choose Copy to SVP. To do that,
- Go to classification data page, choose Select under intent name.
- Choose data you want to export to SVP.
- Then click Copy to SVP.
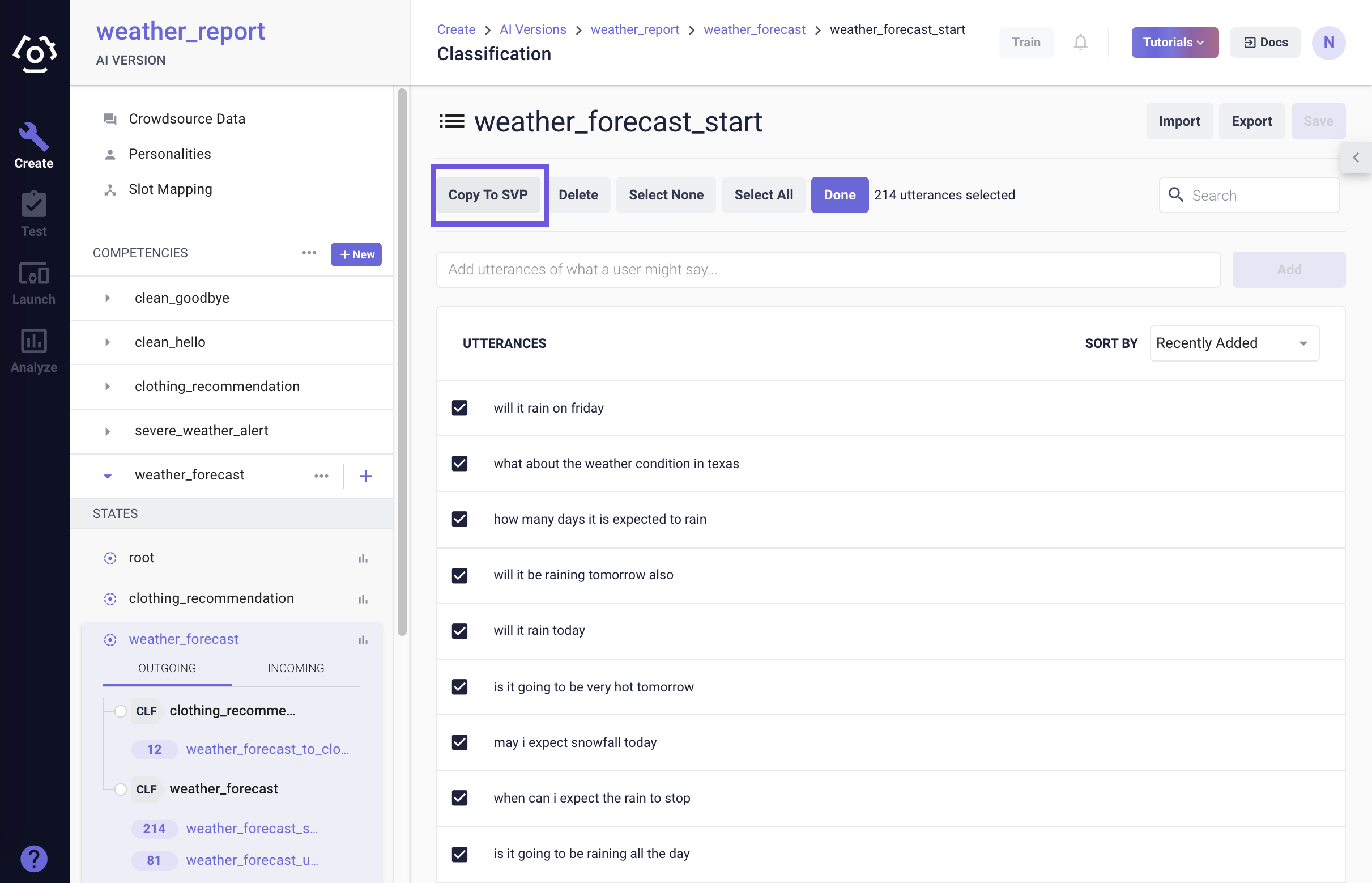
Double click on the slot you are labeling, choose the slot name then the slot is highlighted.
After making changes, click Save Data on the top right to save edits before leaving the page.
Other actions:
Edit utterances by clicking into text and changing the utterance in place.
Remove utterances by clicking on the
 at the end of each row.
at the end of each row.
# Import
On the slot data page, use the Import button to import slot data from a JSON file or a CSV file.
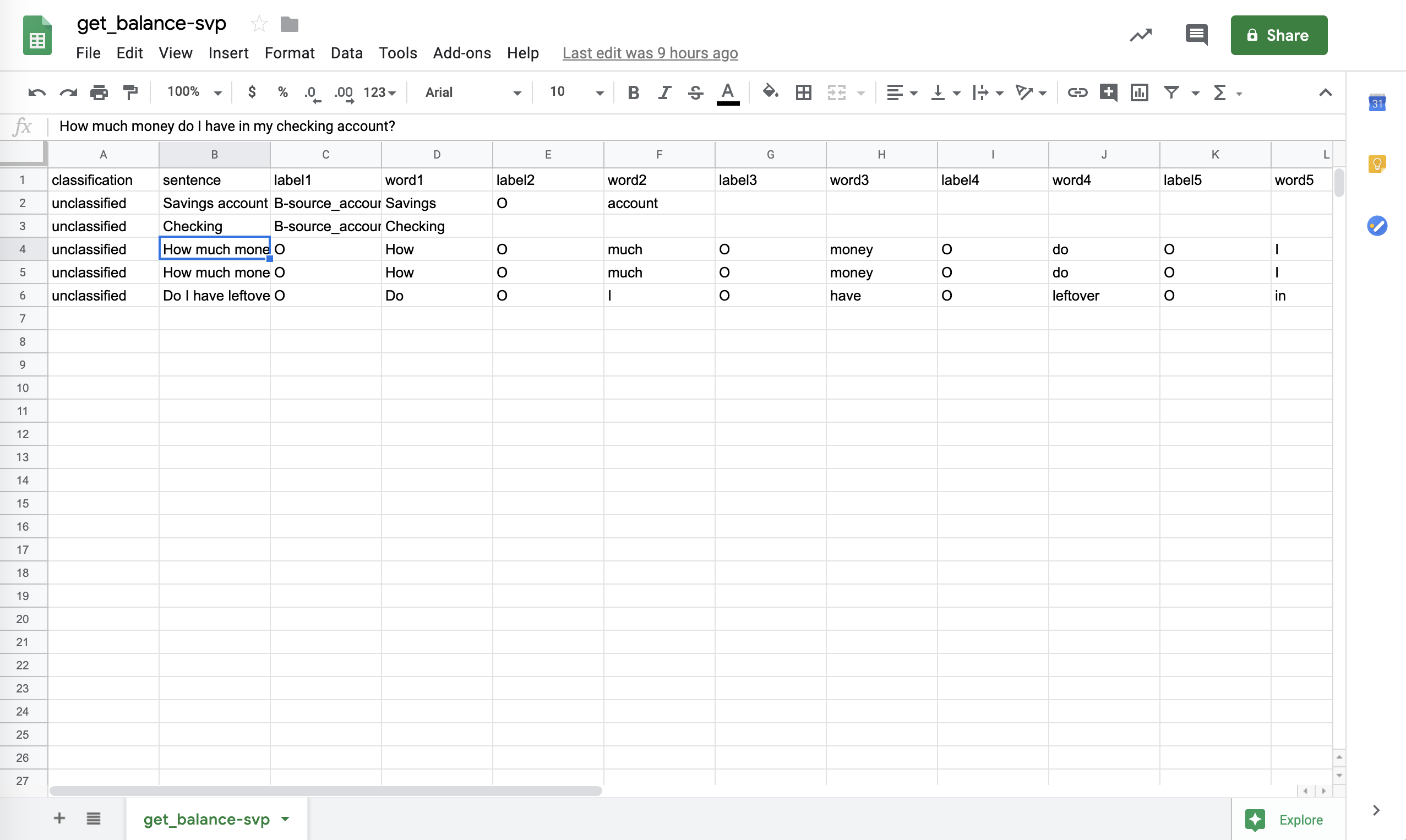
Slot data takes the format as the following:
JSON
{
"sentences": [
{
"classification": "unclassified",
"sentence": "Please transfer $100 to my checking account.",
"svpLabels": [
{
"label": "O",
"word": "Please"
},
{
"label": "O",
"word": "transfer"
},
{
"label": "O",
"word": "$"
},
{
"label": "B-amount",
"word": "100"
},
{
"label": "O",
"word": "to"
},
{
"label": "O",
"word": "my"
},
{
"label": "B-destination_account",
"word": "checking"
},
{
"label": "O",
"word": "account"
},
{
"label": "O",
"word": "."
}
]
}
CSV
Similar to the JSON format, tokens that are belong to a slot are labeled B-slot_name or I-slot_name. 'B' stands for 'beginning', 'I' stands for 'inside'. The rest that should not be labeled as slot values are labeled 'O' which stands for 'outside'.
Note: When importing slot data, we recommend that you import classification data first and then manually label the slots; otherwise you can also import previously labeled data exported from other versions.
# Crowdsource
From your AI workspace, go to your competency control panel and click on Crowdsourcing Data which will take you to the crowdsourcing page.
Click New Slot Labeling Job.
Fill in the modal popped up:
Default Settings:
- Job Name: Name the job for your own reference. It will NOT be visible to the crowdsourcing workers.
- Worker Job Title: The job name that will be posted to the crowdsourcing platform.
- Job Description: A description that is passed to the crowd. Make sure that it includes a descriptive prompt so that the crowd worker knows how to successfully complete the labelling task. Read the Best Practice Tips to learn our recommendation on how to frame the description.
- Example Utterance: Add an example utterance along with labelled slots. A demonstration to the crowdsource workers of how you would label the slots when manually curating SVP utterances.
- Import Jobs: Select the classification job to label. Either from classification crowdsource jobs or from classification data you stored locally.
- Number of Votes Per Slot: The number of crowdsource workers that have to label a value the same way in order for it to be accepted as a valid label. Three is an average vote number but it might vary case by case.
- Reward per Worker: How much the crowdsource workers will be paid for each utterance. The reward must be no more than $0.50. Each worker will provide 5 utterances.
Advanced Settings:
- Job Duration: How long the job will be available on MTurk before expiring.
- Worker Country: You can choose the regions that the crowdsourcers are from. Currently only three countries: China, United States and United Kingdom.
Once all the information is filled in, you are ready to Launch the Job!
Once a job is complete, you can curate and edit the data coming back from the crowdsource workers. Then select the utterances that you would like to add to the training set and click Export to SVP.
Note: We generally recommend that you manually label slot data and by one person per slot. Since labeling consistently is a key factor in the quality of slot data.
Other actions:
- You can also cancel the job at any point of the process.
# How to export slot data?
On the slot data page, use the Export button to export slot data to a JSON file or a CSV file.
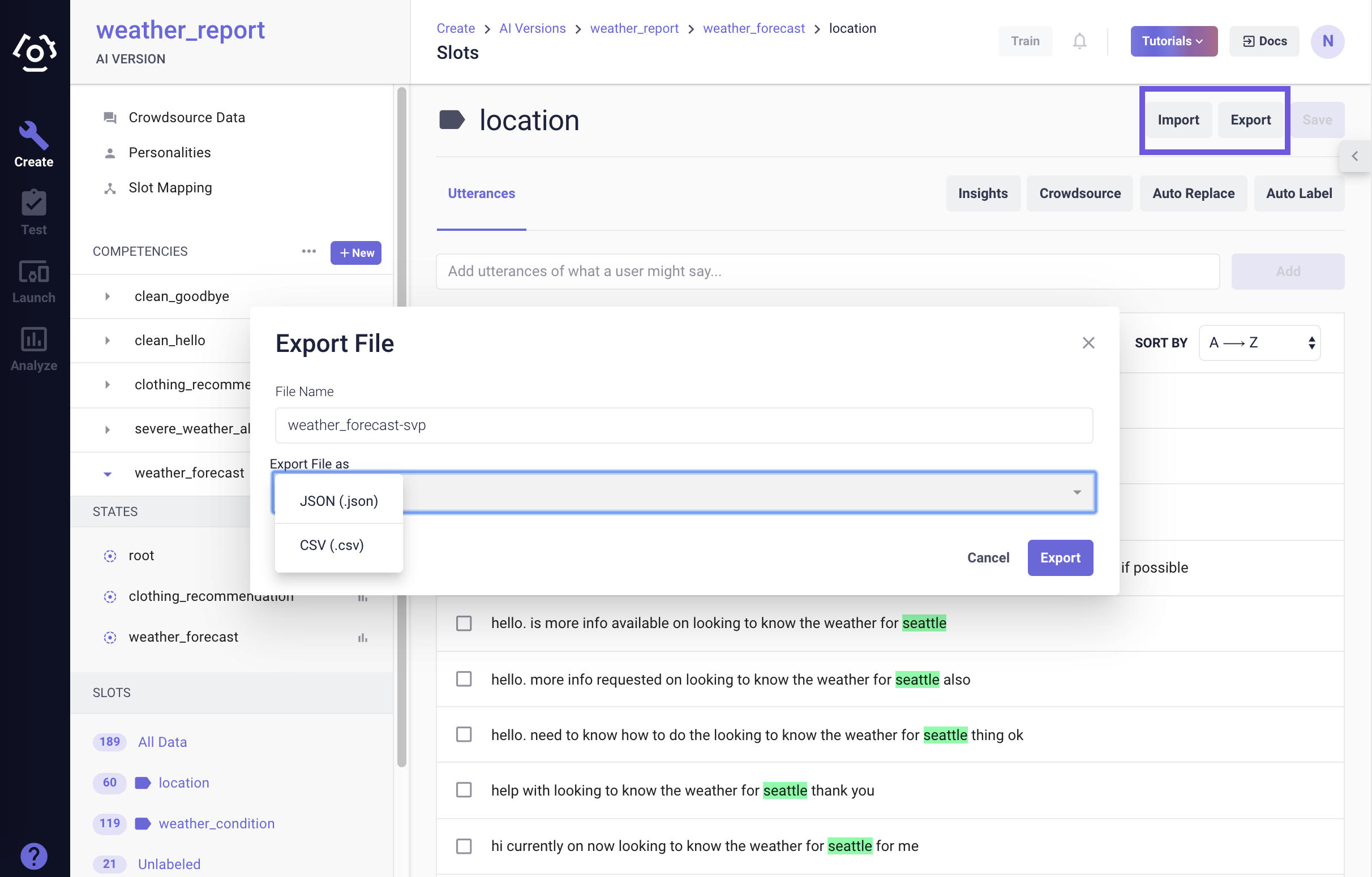
Reference the Import section for the format of each file type.
# How to use Auto Replace and Auto Label?
# Auto replace
Auto Replace allows you to replace a certain slot value occurring in all utterances with another value. It is useful when: 1) you want to correct errors; 2) you are repurposing an existing dataset and the use case doesn't match completely.
To access this feature, click Auto Replace on the top of the slot data page:
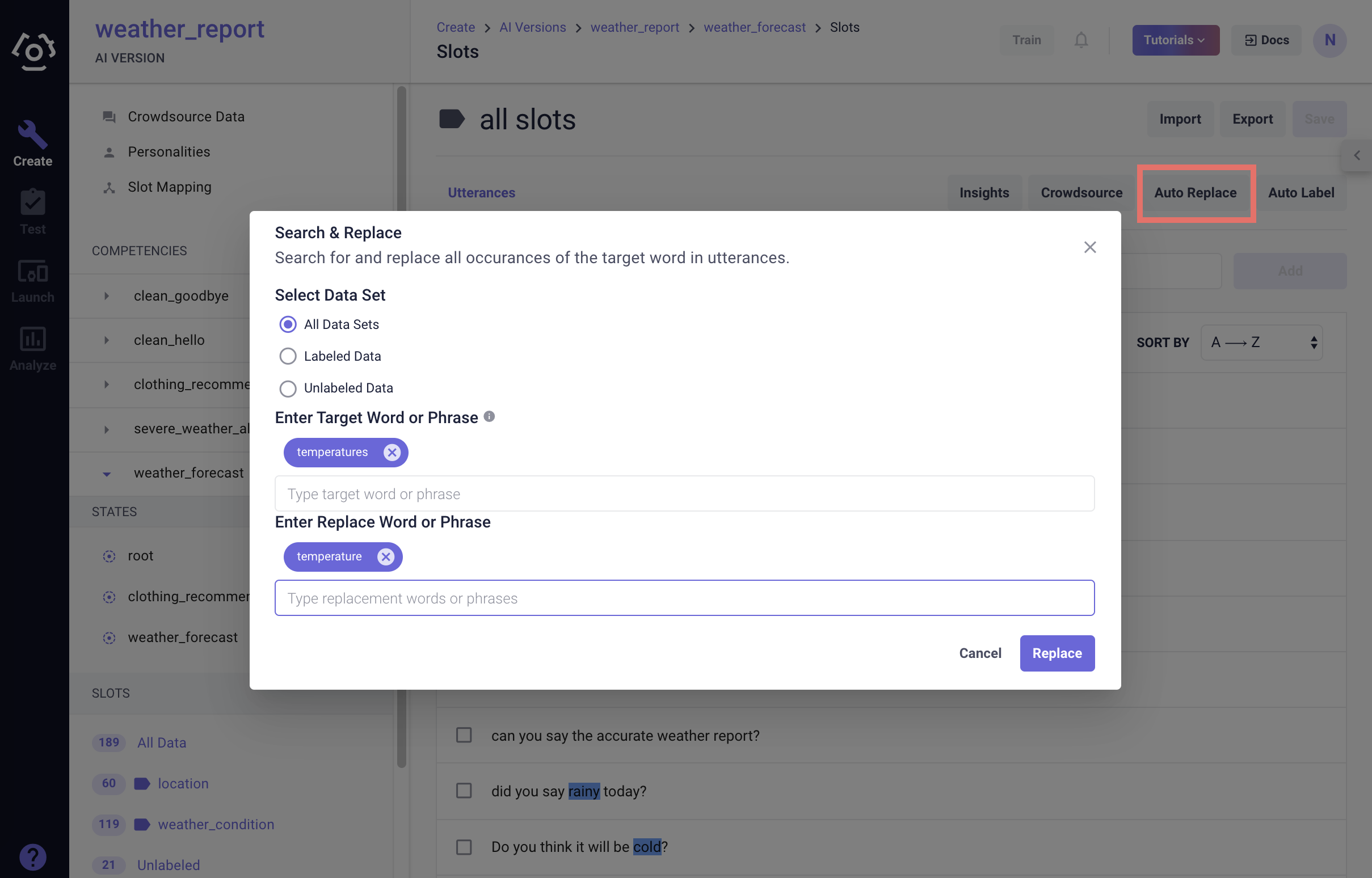
Choose the dataset you wish to perform this action.
Enter a target value and a replacement value.
Note:
- The feature supports one-to-one replacement.
- When you put in a value, always hit enter for the value to register the input should change to a chip placed above the text input area.
# Auto label
Auto Label accelerates the data labeling process. Not only you can leverage this tool to label slot data, but also remove labels.
To access this feature, click Auto Label on the top of the slot data page:
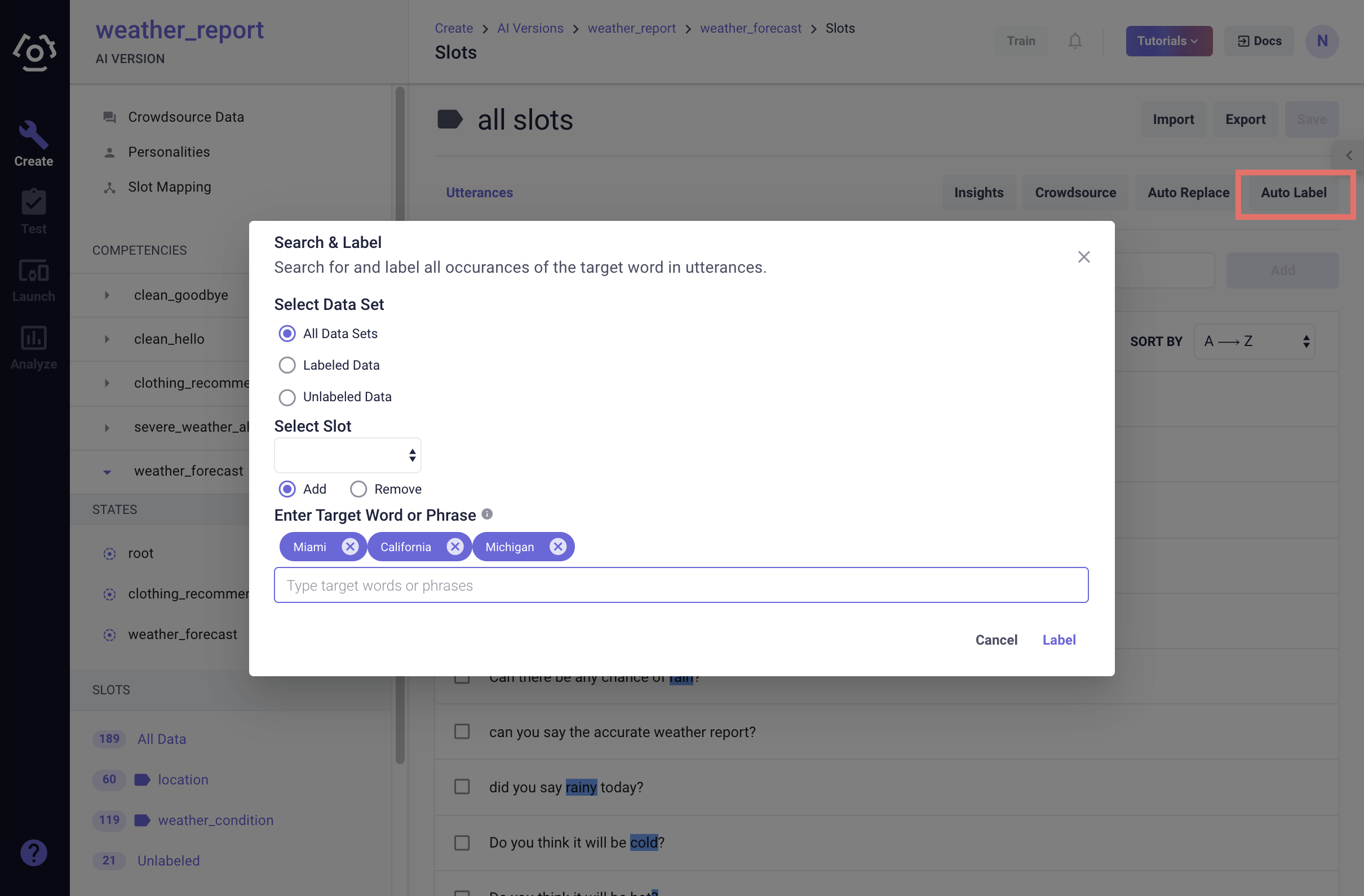
Choose the dataset you wish to label or remove label.
Select slot and choose to add or to remove.
Enter target words or phrases. You can enter multiple targets at a time.
# How to curate slot data?
Data curation is one of if not the most important process that determines the robustness of your AI model. Here is a checklist that we recommend to keep in mind while curating slot data:
The first and foremost is to keep labeling consistently and only label the smallest amount of tokens necessary!
For example you are labeling number of
account_type, you only need to label "checking", "savings", "retirement" etc.Keep a balanced distribution of slot values.
The platform offers the slot data insight tool and the advanced slot data search feature to help you gauge whether your slot data is overfitting to several certain values.
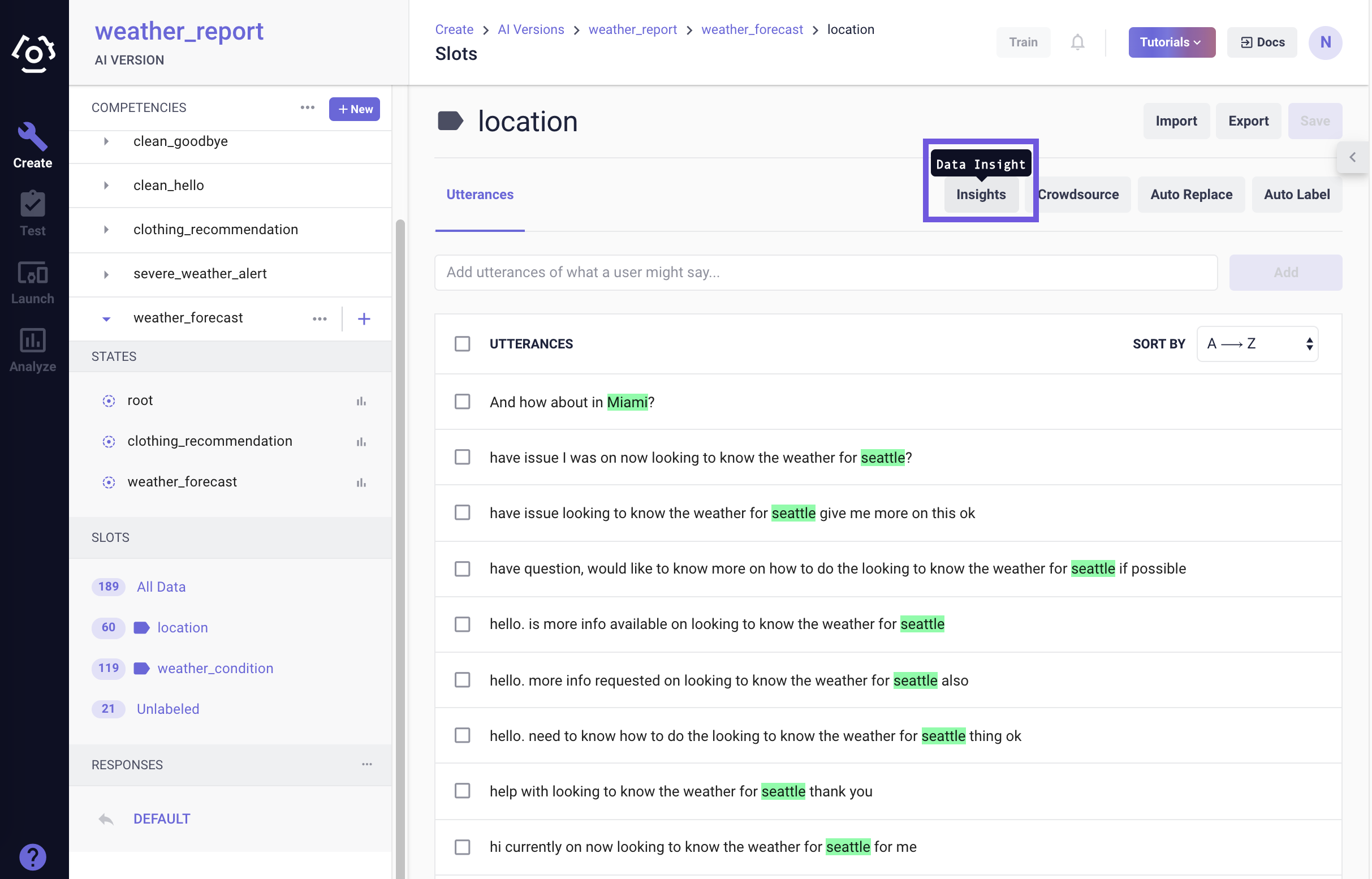
# How to use the slot data distribution tool?
A Slot Data Distribution is a quick and easy tool that provides a simple summary of slot data for a given competency. It simply provides the number of times a token appears as a slot in the competency’s training data.
The tool can help
prevent poor SVP models, and\or
analyze or debug the behavior of SVP models.
To access the slot data distribution tool, go to a slot data page, then click Insights on the top of the page.
You should see a bar chart for slot value distributions within a certain slot.
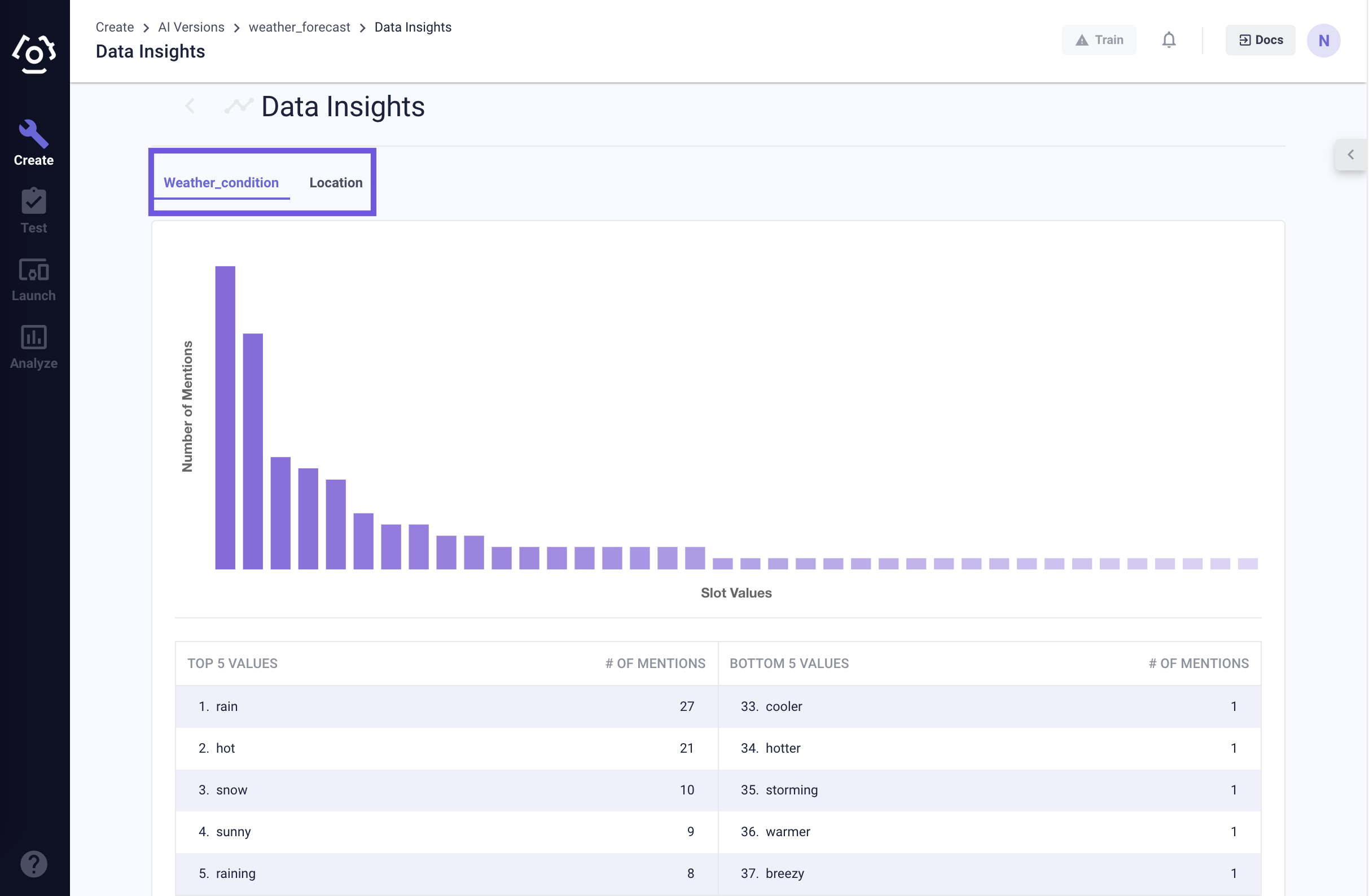
What do we do with the insights?
In general, a more even distribution is better assuming the goal is to get the SVP engine to extract slots on the syntax of the sentence. What you especially want to avoid here is when a single bar in the chart is about or more than 50% of its nearest neighbor. Like most things, this guideline doesn’t apply in all cases. If you see that you are in fact overfitting to that particular slot value, one potential remedy might be to replace a number of the overrepresented tokens with lesser represented tokens.
There may be some cases (very few) where you want to overfit to a value. These cases usually come down to when you want to do keyword matching. However, it is pretty uncommon.
# How to utilize slot-value pairing?
Watch this video on Query classifier vs. SVP (opens new window) to learn how to utilize query classifier and slot-value pairing.
# Best Practice Tips
- What makes data “good”
- Good data can be thought of as a representation of how users interact with the AI. Quality and consistency are important for a good dataset. A high quality dataset requires that its utterances be correctly labelled and added to the proper use case. Consistency is also important and requires that the utterances and words/phrases in the dataset are labelled with the same ruleset and heuristics across the entire dataset.
- What amount is "enough"
- Generally we recommend to have 300-500 utterances for each classification class/label and 600-1000 utterances for each SVP slot for a human-in-the-room level of quality. However, depending on the use case, the number needed can vary. The amount of data required depends heavily on a range of factors, including the complexity of the competency, the diversity of the utterance for the competency, and the other competencies that co-exist in the same AI version (e.g. how close they are to the new competency). Therefore, there is no golden rule for how many utterances you need to have for a competency. Secondly, data collection and curation is an ongoing process, even well beyond the point of the competency prototype. These numbers are minimum amount of utterances you need for a "working" competency prototype with an overage complexity. Continuous dogfooding (opens new window) and data curation are required to improve the competency quality. It is through trying out the competency yourself and on others that you can truly evaluate whether there is enough data.
Last updates: 02/10/2020