# Multi-Intent
# What
# What is multi-intent?
Multi-intent is the ability to handle a single utterance that contains more than one intent, which is critical to achieving natural human interactions.
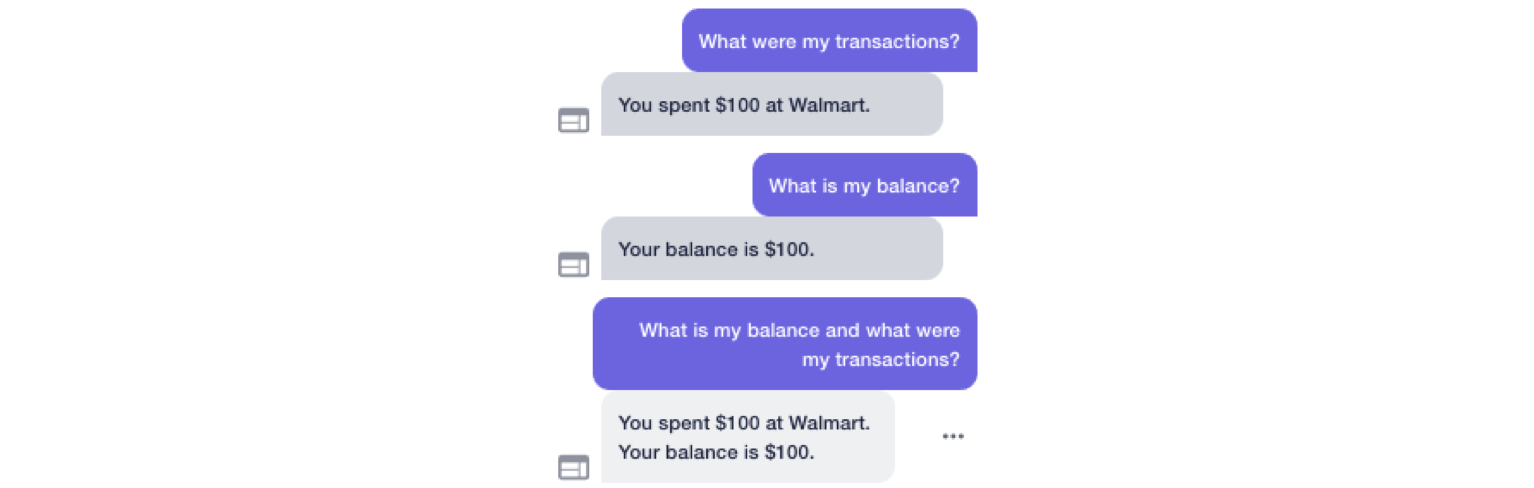
In the demonstration above we can see that not only did the AI model picked up multiple intents in the query, but also it responded to each intent accordingly.
Traditionally, most other systems treat multi-intent as a single-intent classifier problem. However, this is not rigorous since it is hard to cover all possible pairing of intents and increases the effort of data collection exponentially.
We handle the multi-intent problem by introducing a segmentation model. The segmentation model is data-driven and it separates the utterance into single-intent segments that are processed sequentially.
For example:
Query: "I want to make a payment, but let me see my balance."
I want to make a payment, <SPLIT> but let me see my balance.
["I want to make a payment" → `make_payment_start`, "but let me see my balance" → `balance_start`]
Intent: ["make_payment_start", "balance_start"]
# What is the segmentation model and how does it work?
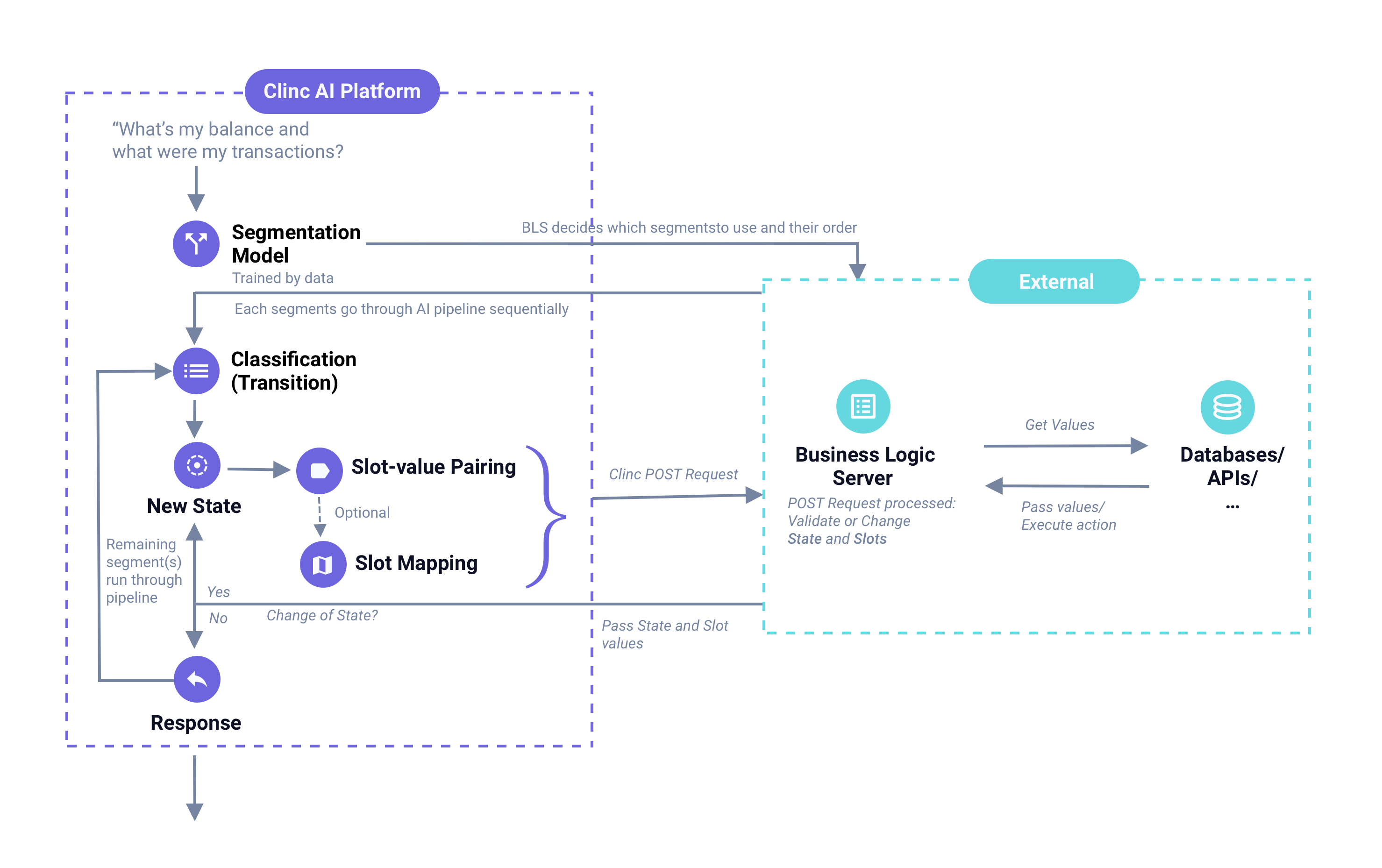
The segmentation model runs at the front of the AI pipeline. It splits the utterance into meaningful segments then passes them to business logic server where your pre-configured code will decide which segments to handle and the order to handle them. Then each segment runs through the AI pipeline sequentially. The AI will then concatenate each of the responses. See the graph below:
# What kind of data is needed to train the segmentation model?
We suggest that you read this section along with the How to implement multi-intent into your AI version?
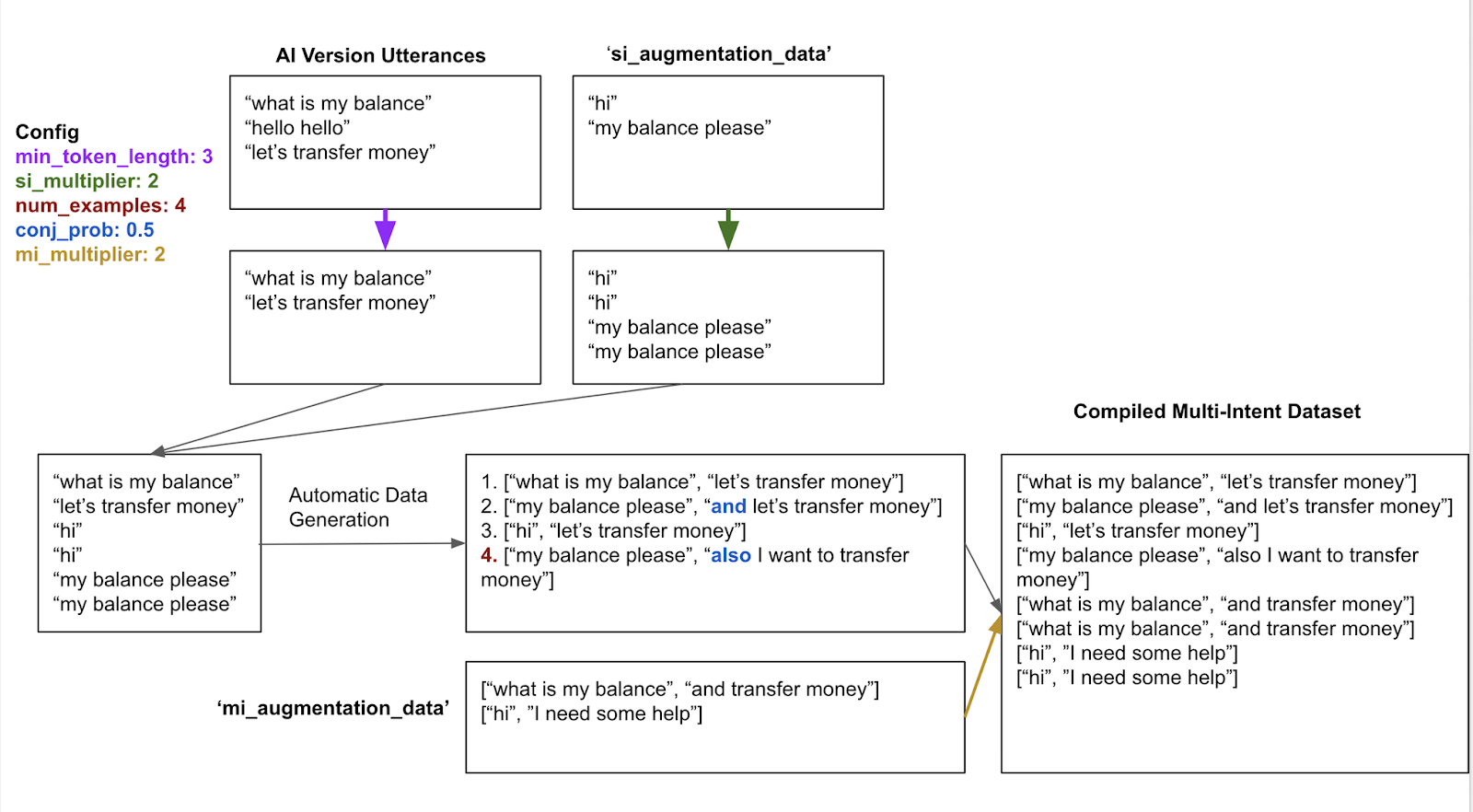
In the diagram you can see that the segmentation model leverages the data that's already in the AI version and auto-generates a multi-intent dataset for training.
Adding single-intent and multi-intent data (si_augmentation_data and mi_augmentation_data in the diagram) is largely to provide you the ability to fine-tune the model (e.g., observe a pattern in how segmentation is performing incorrectly, then add data to address that problem).
If you're auto-generating data, both single-intent and multi-intent data are optional to import into the platform. If you're not auto-generating data, then multi-intent data is required to be imported.
When importing data, the dataset should conform to the following format:
{
"singleIntent": [
"is it gonna be hotter in Seattle",
"is it likely to rain today",
"can i take off a bit early today"
],
"multiIntent": [
[
"is there chance of rain",
"What do I have in the afternoon"
],
[
"will it rain in Texas tomorrow",
"What time does the meeting start"
],
[
"what is the low for tonight",
"When's my last meeting"
]
]
}
# How
How to implement multi-intent into your AI version?
How to configure BLS for multi-intent?
# How to implement multi-intent into your AI version?
In the competency sidebar, you can find the multi-intent page.
Note: To implement multi-intent, you first need to have a completely built out version.
On the Multi-Intent Configuration page, make sure that the feature is enabled.
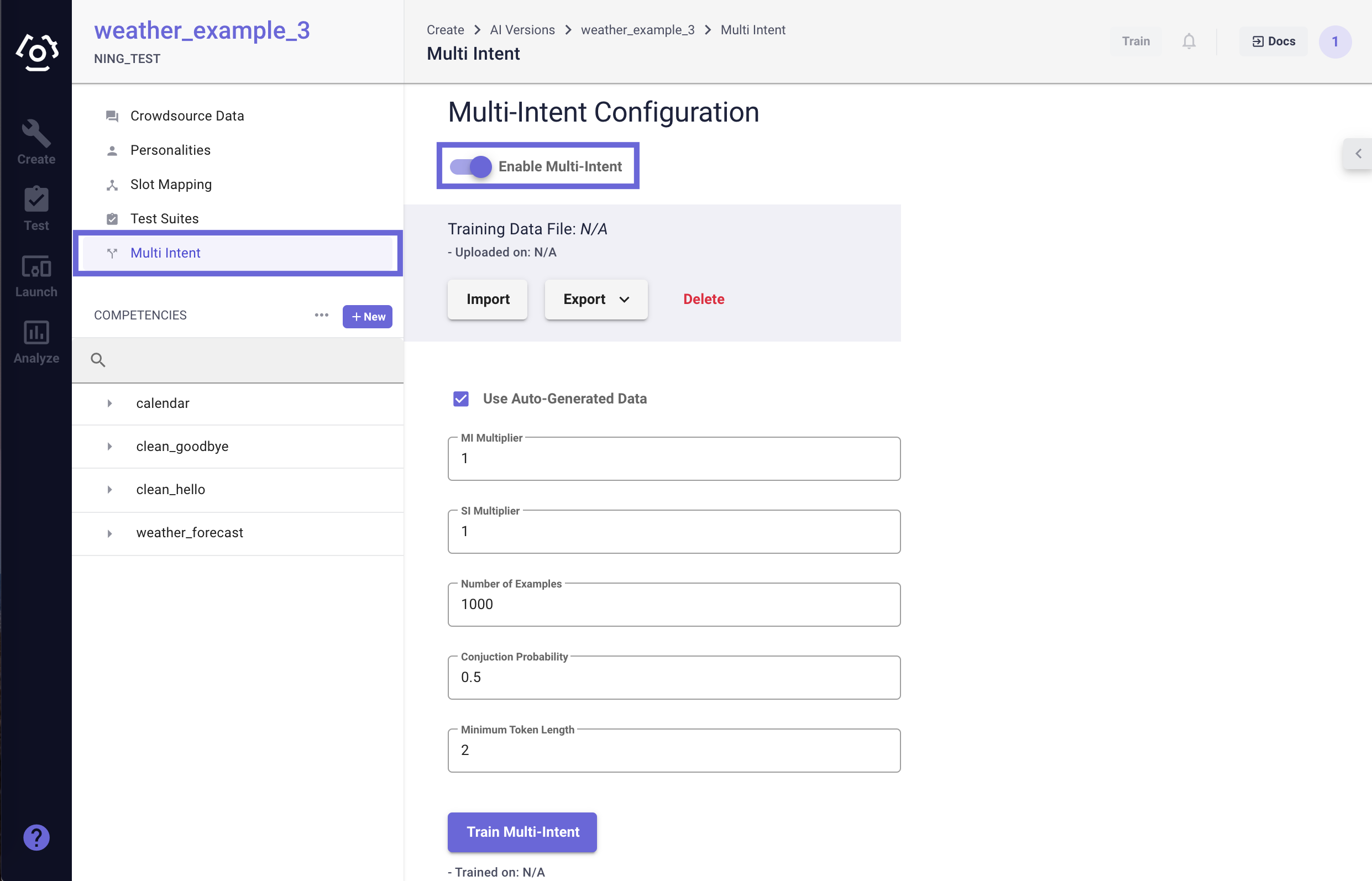
| Configuration | Explanation |
|---|---|
| MI Multiplier | In the scenario in which you want to increase the priority of the mi_augmentation_data you are adding, you can increase the mi_multiplier. This will add multiple copies of the mi_augmentation_data utterances to the segmenter model, effectively increasing the priority of the augmentation data utterances. Default is 1. |
| SI Multiplier | In the scenario in which you want to increase the priority of the si_augmentation_data you are adding, you can increase the si_multiplier. This will add multiple copies of the si_augmentation_data utterances to the segmenter model, effectively increasing the priority of the augmentation data utterances. Default is 1. |
| Number of Examples | The total number of auto-generated utterances to train on. This does not include custom data (i.e mi_augmentation_data). The training data is generated by randomly sampling the classifier and SVP datasets and concatenating them into multi-intent utterances with or without the use of conjunction (e.g. “and”). Default is 1000. |
| Conjunction Probability | This is the probability of adding conjunction to a multi-intent utterance (e.g. and, also). Default is 0.5. |
| Minimum Token Length | The minimum length of a single intent utterances to combine into multi-intent utterances. Default is 2. |
Once you have configured each field, you can click Train Multi-Intent to train your segmentation model.
# How to configure BLS for multi-intent?
Once segmentation is enabled on an AI version each query request will make a BLS call that includes classified_segments in the request. This will include each of the segments found in the query along with their classified state.
"classified_segments" = [
["what is my balance", "get_balance_start"],
["and what were my transactions last week", "transactions_start"]
]
The expected response from the BLS must include ordered_segments which will be a list of utterances in the order you wish to process e.g.
"ordered_segments" = ["and what were my transactions last week”, "what is my balance"]
When the platform receives the response, it will process each of the utterances in ordered_segments in the specified order. The AI will concatenate each of the responses.
Here's a sample snippet:
Code Snippet
def prioritize_multi_intent(response):
segments = {state: utterance for utterance, state in response["classified_segments"]}
print("Segments")
print(segments)
goal_states = ["get_balance", "transactions_start"]
ordered = []
for state in goal_states:
if segments.get(state):
print("Appending segment utterance")
ordered.append(segments.get(state))
if all(ordered):
response["ordered_segments"] = ordered
else:
print("Failed to validate ordered segments")
print("response segments")
print(response["ordered_segments"])
return response