# Classification
# What
# What is classifier and classification?
When an end user queries an AI, the AI determines which transition to take and which state to land on by processing the query through an AI engine called a classifier (used interchangeably with query classifier/QC). This process that determines the direction of the next turn in the conversation is called classification. Notice that every query comes into the platform will be classified first. During this process, the classifier engine assign a label to the query and then maps it to an existing intent and take the classification transition that the intent is associated with.
Classification data is used to train the classifier engine to make decisions on queires. For example, if the user has an intent called food_order in their training dataset, when an end user says "I want a burger", this utterance is likely to be mapped to that intent. As a conversational designer, they will want to make sure the classification data for their competencies have a wide variety of "utterances" (ways of saying something) so that their AI will be able to respond correctly to natural and messy human expressions.
# What is an intent?
An intent is a collection of data with which the user train classifier engine. User would normally assign a label upon creating an intent. Two most common intent labels that we use in the Platform are: competencyname_start and competencyname_update.
There are also a list of pre-built intents in the Platform that can be used for model training:
- clean_hello_start
- clean_goodbye_start
- cs_yes
- cs_no
- cs_cancel
# What is the difference between adding a new classification transition and adding an intent to an existing classification transition?
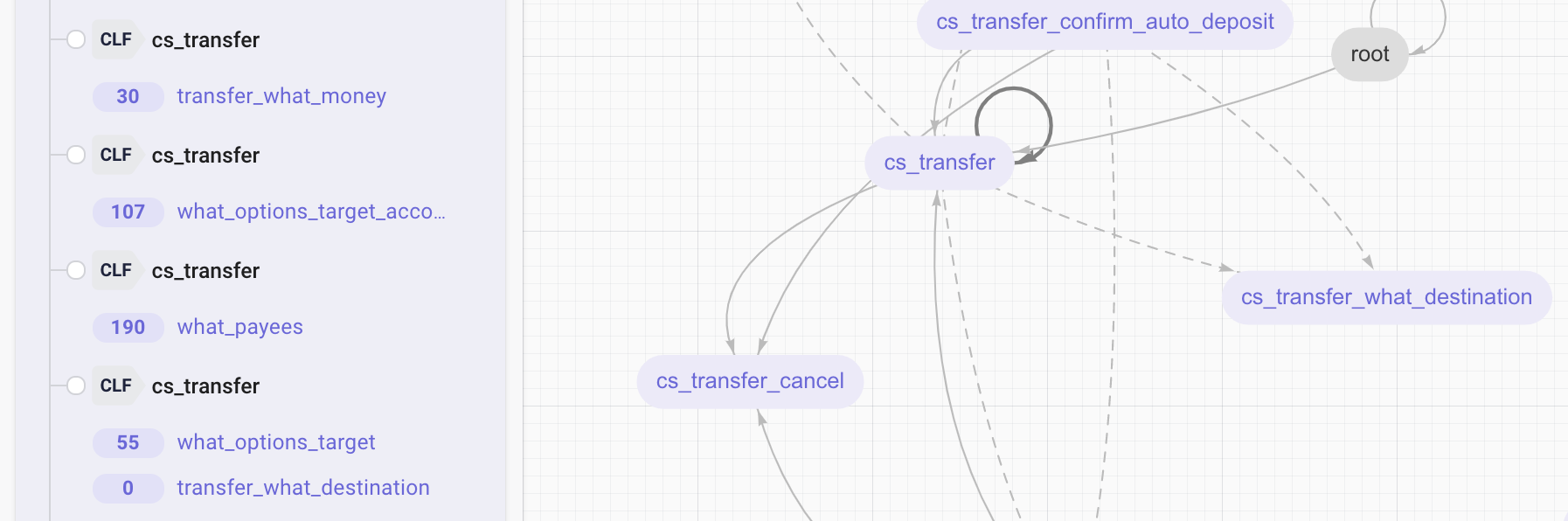
The user can either add a new transition or add an intent to an existing transition (see graph below). Adding an intent is almost like adding the data to the existing except on classification there is intent1&intent2(in response payload). If another classification transition is added they "compete" with each other for classification which could lower either or their respective scores for classification. With individual intent, the user can also configure action/response specific to this transition through Business Logic which provides more customizability.
# How
How to collect classification data?
How to export classification data?
How to curate classification data?
How to use the uniqueness sorting tool?
How to use the classification data insight tool?
How to utilize query classifier?
# How to add/remove an intent?
There are two ways to go about creating an intent:
By adding a classification transition, the user needs to specify the intent. User can choose an existing intent or Enter your own. See [How to add different types of transitions?](states&transitions.html#how-to-add-differenct-types-of transitions)
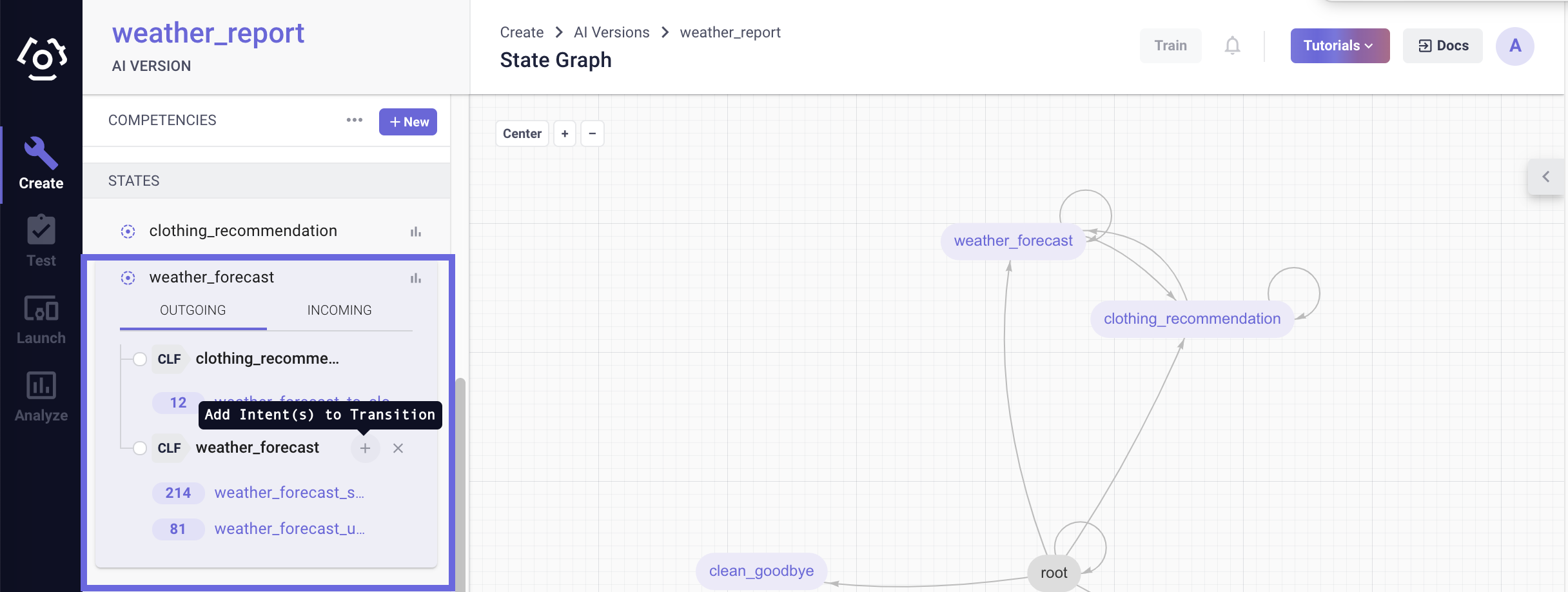
Users can also hover over the classification transition to which they wish to add an intent, click on
 to reveal the add intent field.
to reveal the add intent field.
To remove an intent, hover over the intent name and the user should be able to see  . Generally the ones that link root to the competency cannot be removed.
. Generally the ones that link root to the competency cannot be removed.
# How to collect classification data?
Generally in the Clinc AI Platform, there are three ways to collect classification data:
- Manual Entry
- Import
- Crowdsource
- Generation
# Manual Entry
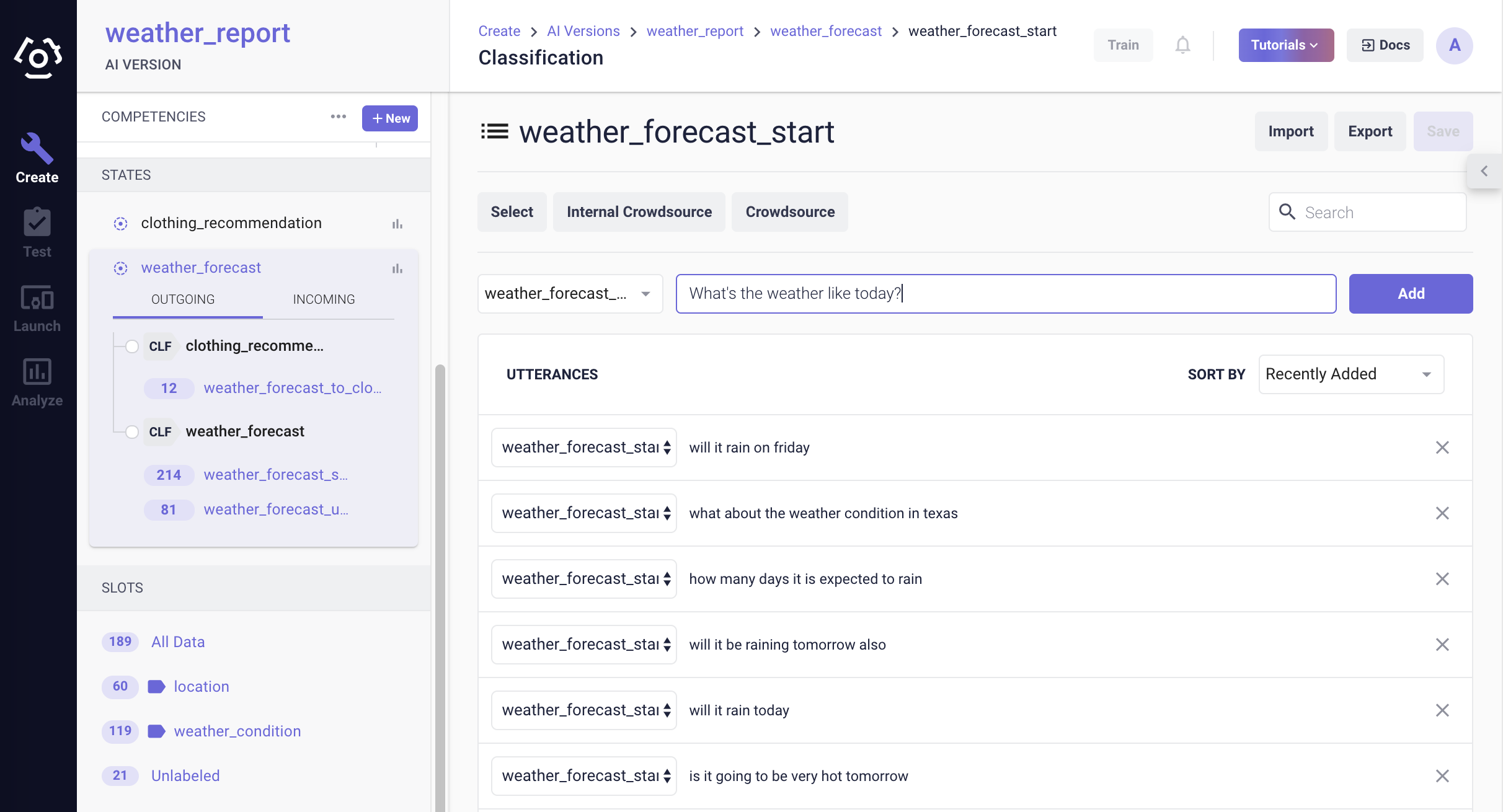
From the detail sidebar, select the competency/state/transition, click on the intent to which one would like to add data. If a user needs to add a new intent, see How to add an intent?
On the data curation page, type in utterances in the Add utterances field one at a time and click Add.
After making changes, click Save Data on the top right to save edits before leaving the page.
Other actions:
Edit utterances by clicking into text and changing the utterance in place.
Remove utterances by clicking on the
at the end of each row.
# Import
On the same classification data page where data is added manually, the Import button can be used to import classification data from a JSON file or a CSV file. Take get_balance as an example, the uploaded classification data file needs to be in one of the following formats:
JSON
{
version:1,
"data": {
"get_balance_start": [
"Can you tell me the balance for my savings account please",
"I want my balance",
"I want the balance for my checking account",
"I'd like to know how much money is currently in my savings account"
]
}
}
or
{
"Can you tell me the balance for my savings account please": "get_balance_start",
"I want my balance": "get_balance_start",
"I want the balance for my checking account": "get_balance_start",
"I'd like to know how much money is currently in my savings account": "get_balance_start"
}
CSV
Similar to the JSON format, the user will have the intent name in the first column and utterances in the second column.
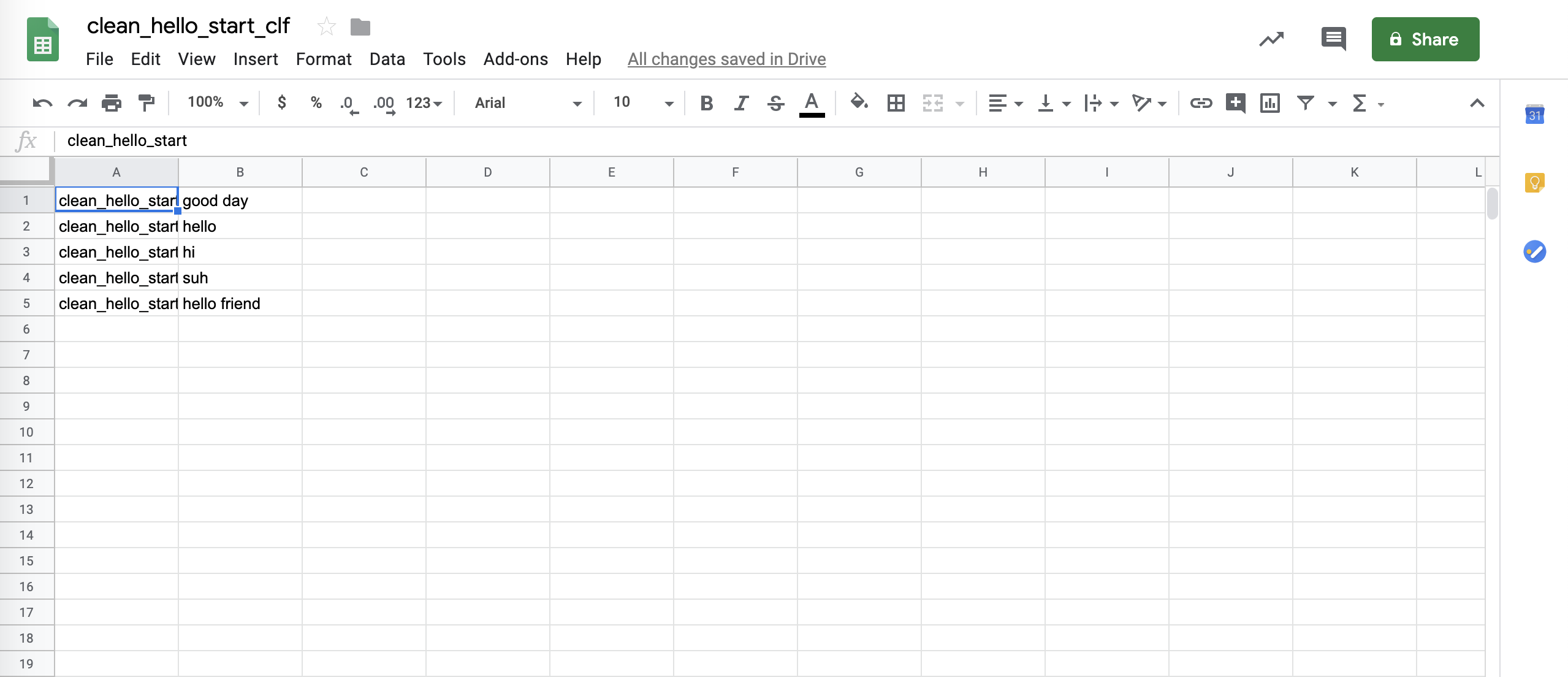
If the format is validated, the utterances will be imported and appear in the data view for their corresponding intent.
# Crowdsource
User can either click the Crowdsource button (below Import and Export) on the data page. Or from their AI version workspace, go to Crowdsourcing Data in competency sidebar.
Click New Classification Job.
Fill in the modal popped up:
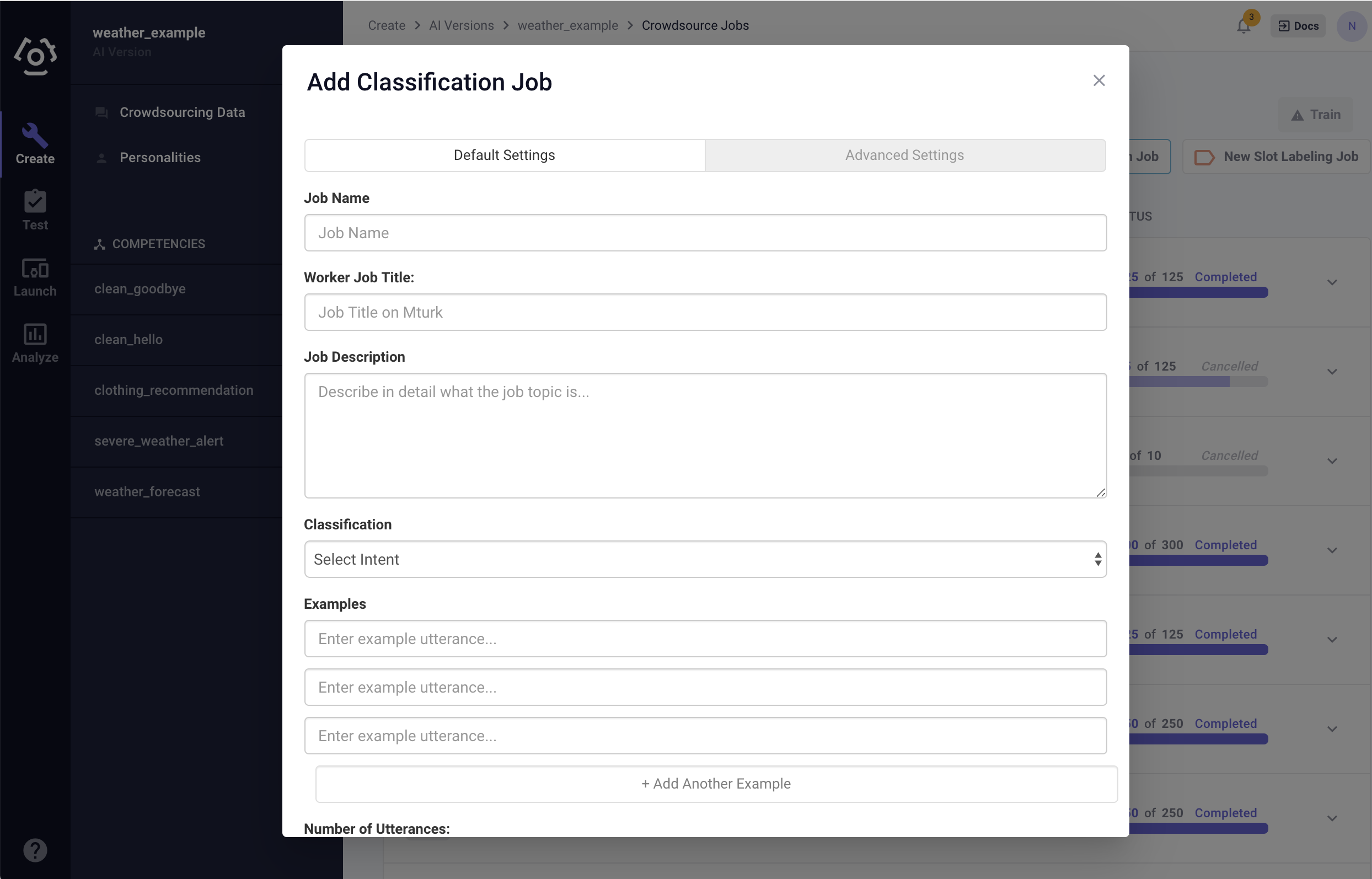
Default Settings:
- Job Name: Name the job for reference. It will NOT be visible to the crowdsourcing workers.
- Worker Job Title: The job name that will be posted to the crowdsourcing platform.
- Job Description: A description that is passed to the crowd. Make sure that it includes a descriptive prompt so that the crowd worker knows how to successfully complete the labelling task. Read the Best Practice Tips to learn our recommendation on how to frame the description.
- Classification: Select the intent for which data is being collected.
- Example Utterance: Provide at least three example utterances to demonstrate to the crowdsource workers the kind of utterances being collected.
- Number of Utterances: Number of utterances being collected. It should be a multiple of 5, and no greater than 500.
- Reward per Worker: How much the crowdsource workers will be paid for each utterance. The reward must be no more than $0.50. Each worker will provide 5 utterances. MTurk charges an additional 20% fee, on top of the reward per worker.
Advanced Settings:
- Job Duration: How long the job will be available on MTurk before expiring.
- Worker Country: Users can choose the regions that the crowdsourcers are from. Currently only three countries: China, United States and United Kingdom.
Once all the information is filled in, user is ready to Launch the Job!
Once a job is complete, click on the job title to review the results. It's time to curate the classification data.
Other actions:
- User can also cancel the job at any point of the process.
# Generation
To generate Classification Data, users can click the Generate button on the Clf Data Generation listing page. Generation is preformed with a Large Language Model (LLM). A user can create an AI Model Connector to select the LLM they wish to use to generate classification data. The button is located near the top left of the classification data listing page and to the right of the Crowdsource button. Below is a list of steps a user can follow to generate.
Click the Generate button on the classification data listing page. After clicking the button, a user should see a dialog appear in the middle of the screen.
Fill in the dialog with the required data. Below is a description of each field that a user will see in the generation dialog form.
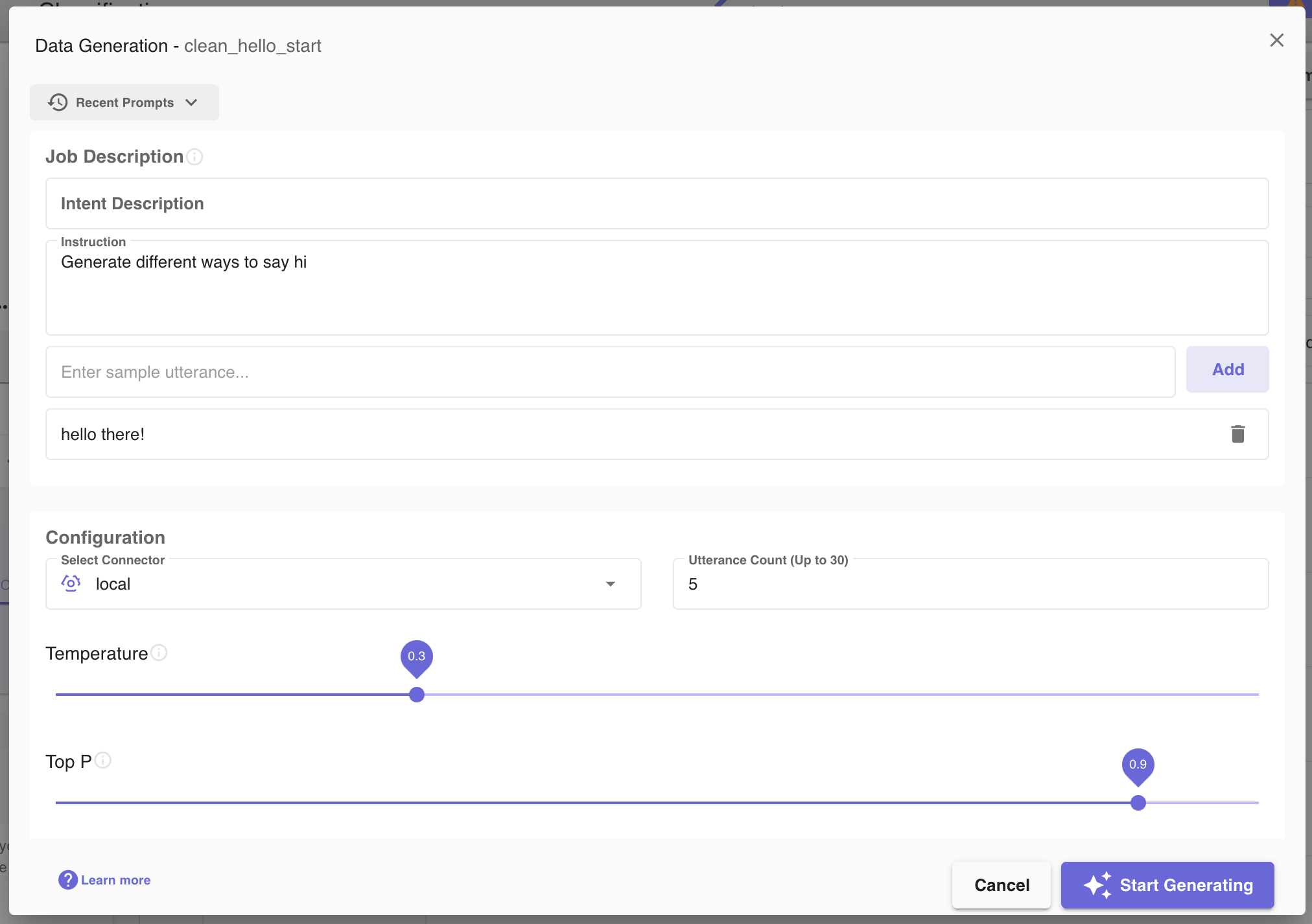
- Job Istruction: A short and specific prompt that is used to shape the output of the generated utterances. This field is required.
- Intent Description: A description of the target intent we're generating utterances for. Ex:
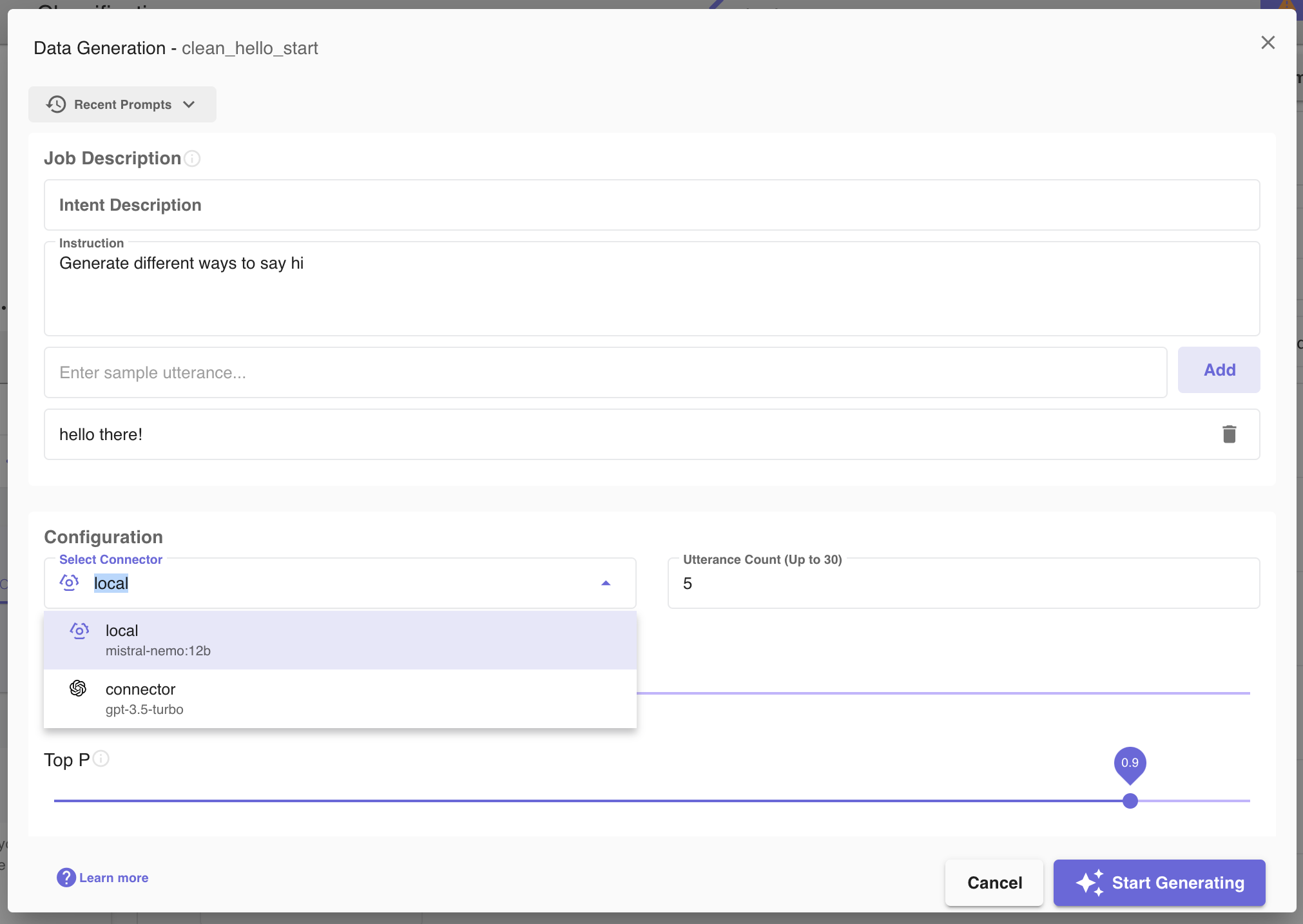
Different ways to say "hello". - Select Connector: AI Model Connectors can be created on the Access Management page and then used to select which Large Language Model will perform the generation (shown below). Select the connector which will execute the generation job in this dropdown. The Clinc local model uses the Mistral AI Model and it will be the default and only option if no other connectors were created.
- Utterance Count: This field collects the number of utterances the user is collecting. It should be at least 1 and no greater than 10 for the local model and no greater than 30 for any OpenAI models.
- Sample Utterance: Provide example utterances (max of five utterances) to be used as a template for generation.
- Temperature: Move the sliding bar to adjust the temperature. The available values are 0.0 to 1.0. Values close to 0.0 will have predictible outcomes and values closer to 1.0 will experience more randomness.
- Top P: Move the sliding bar to adjust the Top P Value. The available values are between 0.0 and 1.0. This controls how creative or predictable the generated text will be. A higher Top P value, such as 0.9, allows for more variety and different word choices, making the output more creative. A lower Top P value, like 0.2, results in more focused and predictable text, using only the most likely words.
Submit the job once the form is complete. A job may take up to a few seconds. Upon job completion, the user will have two main options. A user can either save the generated utterances by selecting the Save button or delete and regenerate the utterances by selecting the Delete Utterances and Re-Generate button. If a user wishes, they can modify the prompt prior to re-generating new utterances. Additionally, the user can delete any unwanted utterances and save only the remaining ones.
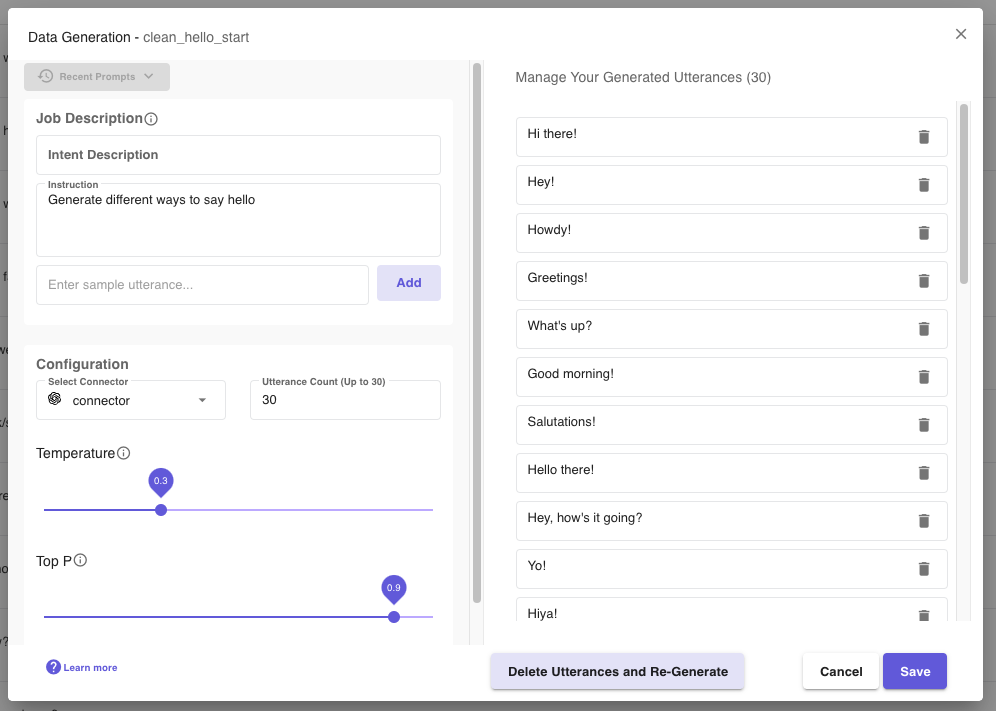
Before clicking on Delete Utterances and Re-Generate, the option to edit the job description before generating again is possible.
Once a user saves the generated utterances, the configuration used to generate those utterances will be accessible through the
Recent Promptsdropdown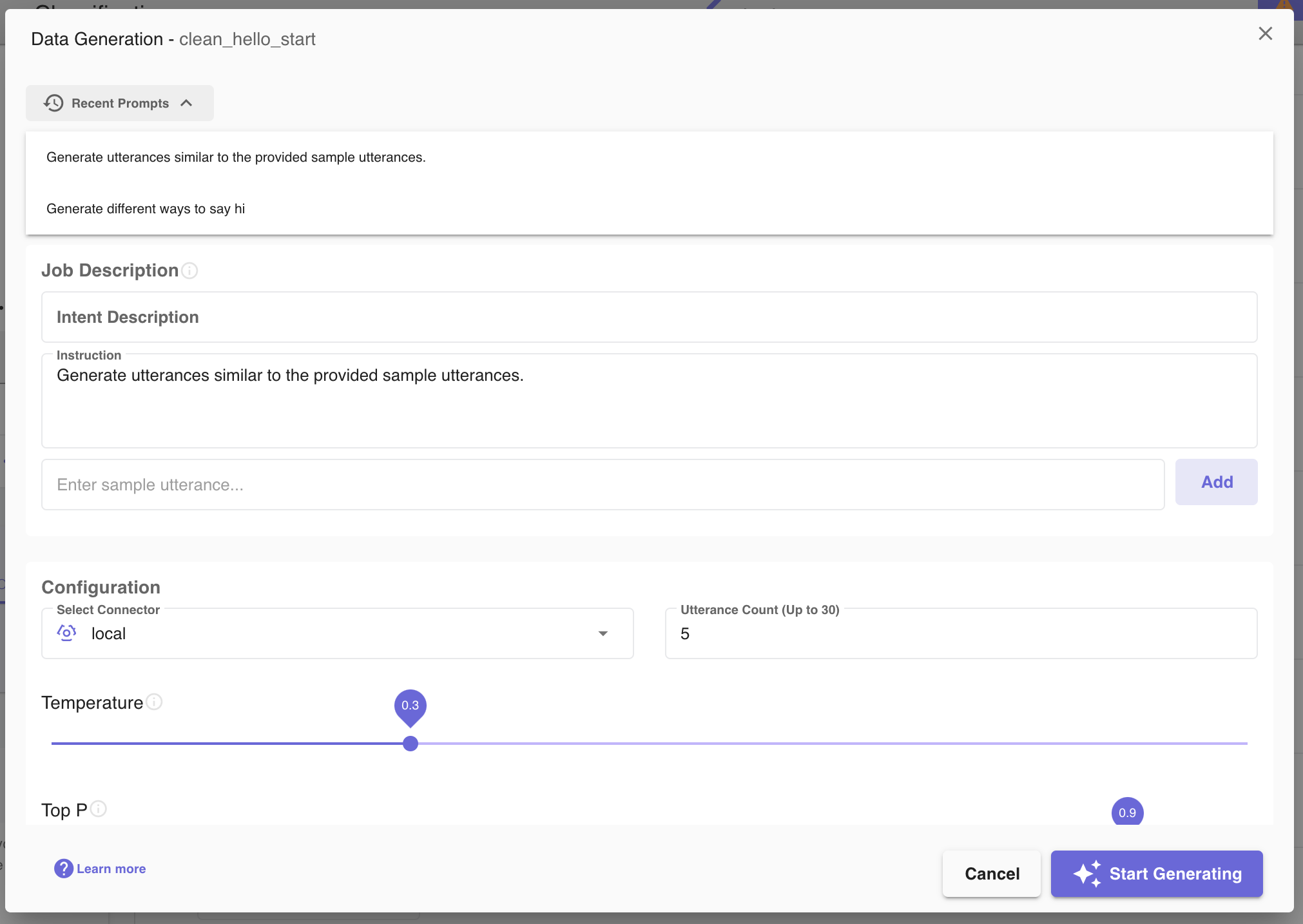 . Clicking on previous prompts will automatically fill the prompt to use the same settings that were used in the previous prompt.
. Clicking on previous prompts will automatically fill the prompt to use the same settings that were used in the previous prompt.
# How to export classification data?
On the classification data page, use the Export button to export classification data to a JSON file or a CSV file.
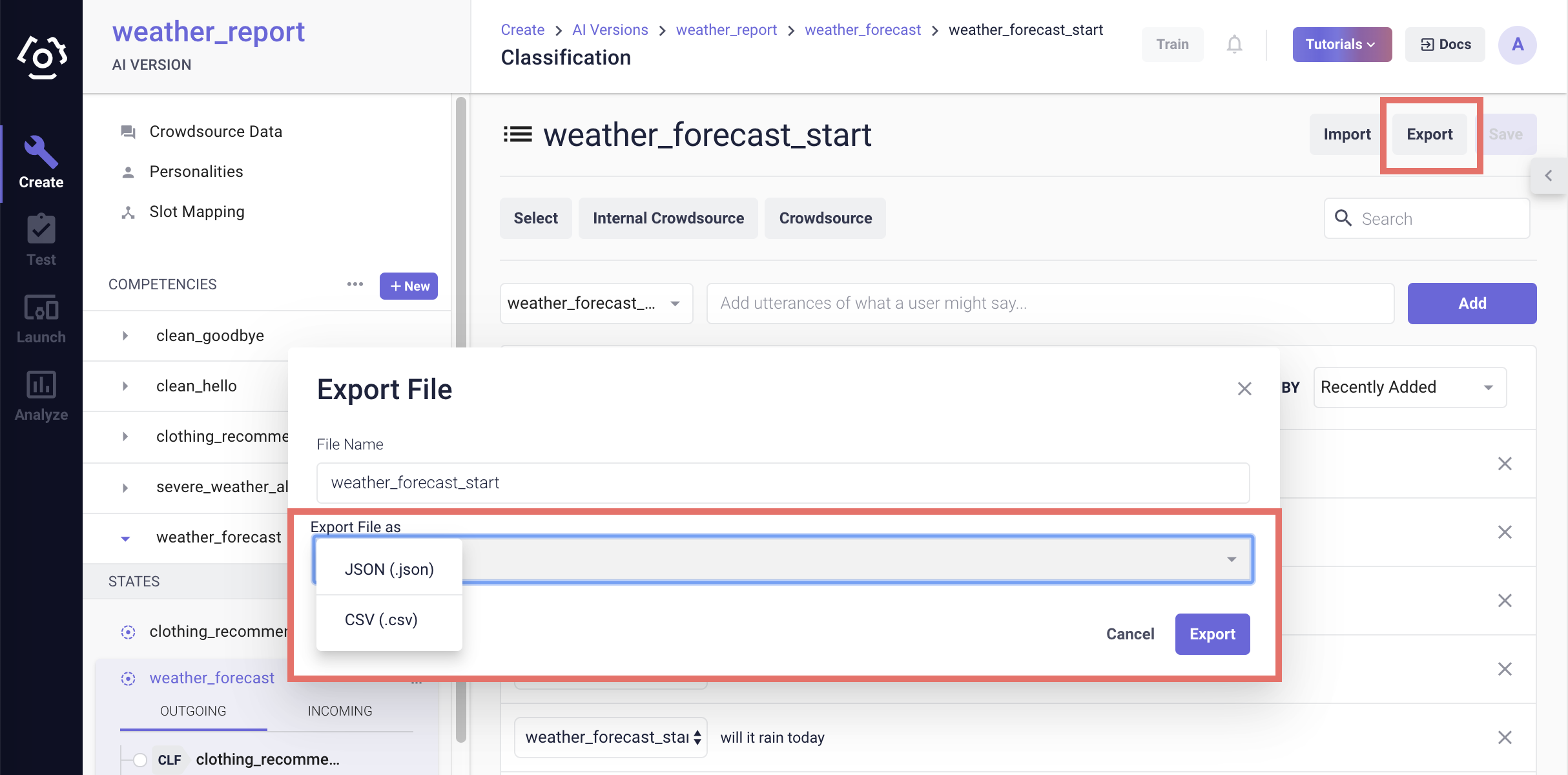
Reference the Import section for the format of each file type.
# How to curate classification data?
When the crowsource job progress reaches 100%, the user is ready to curate the data. This process is just as important as collecting. Here is a checklist that we recommend to keep in mind while curating:
- Make sure that all utterances fit the job description i.e. fits within the competency and represents the intent that is being collected for the utterances. For example if the user is collecting data for food_order_start, an utterance like "actually change the burger to a sandwhich" does not fall under the intent.
- Do not delete typos, slang, incorrect grammar, etc. Utilizing the typos to better represent "messy" human language.
- “Is this teaching the AI something new?” Make sure to delete copy cat utterances.
- Make sure there's a variety of data that is representative of all the ways someone could give a query.
- Collect data at different granularity: capture ways people say about something (the intent the user is collecting data for) as much as possible.
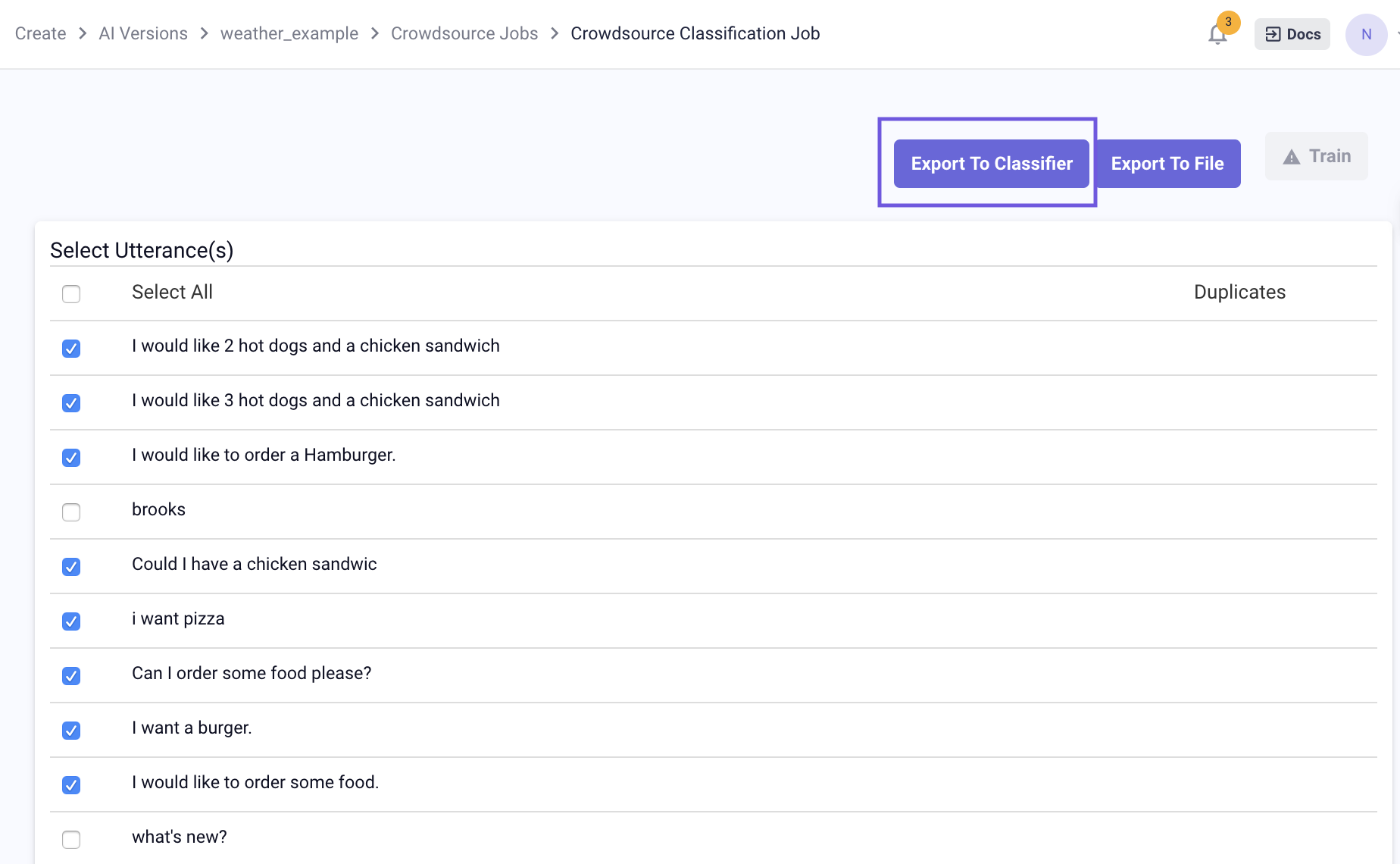
To curate classification data:
Click View Results on the crowdsourcing page. A list of utterances provided by crowdsource workers will be shown.
Deselect the ones (or delete later from the classification data page) that doesn't fit the job description/competency/intent. The user can also edit the utterance.
Once the dataset has been curated, the user can click Export to Classifier to export the utterances for training purpose. Then the intent that the utterances are training can be selected. If an utterance is successfully exported, its row will be greyed out.
# How to use the uniqueness sorting tool?
The uniqueness sort tool provides two main functions:
help identify errors;
help identify unique and underrepresented training samples.
Errors are training samples that are either noise (i.e. out-of-scope) or are mislabeled with the wrong intent. Underrepresented training samples are samples that deviate significantly from the lexical norm within an intent. This means that the words used in the underrepresented training sample are more unique than most of the other samples within an intent.
To access the uniqueness sort tool for an intent, navigate to the intent’s data page:
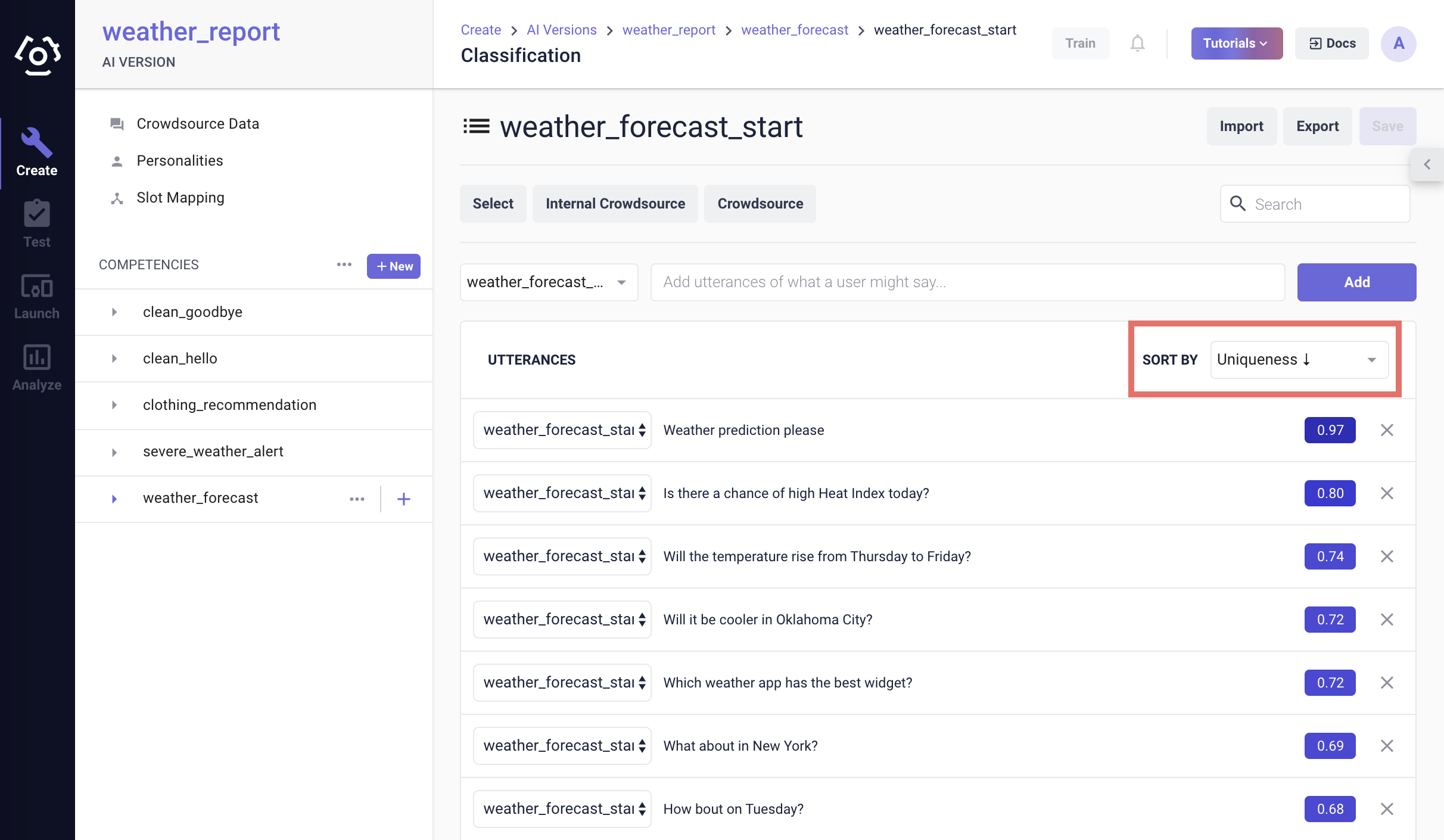
Select the Uniqueness ascending or descending in the SORT BY dropdown.
After a moment, the tool displays a uniqueness score. The higher the score, the more unique the utterance is.
When an utterance gets a high uniqueness score, that can mean either it is erroneous, irrelevant to the intent or this is a more unique way of expressing the intent compared to the rest of the data within the intent. In the example above, the utterances “Which weather app has the best widget?” is clearly irrelevant to my_balance_start intent. But the first one “Weather prediction please” is a valid query. With underrepresented data, the user should consider collecting more diverse training data. One good practice can be using the unique sample as an example in a new crowdsourcing job.
Note: The uniqueness scores are computed per intent, the scores should not be compared across intents.
# How to use the classification data insight tool?
The goal of the classifier weight analysis tool is to provide an estimate as to how heavily certain words are weighted within an intent classifier. We call the score of a weight an “Influence Index”. If a word has a high influence index for a given intent, then the intent classifier gives that word high importance and a query containing that word is more likely to be classified as that intent.
To access the classification data insight tool, click  , a data insight modal will appear.
, a data insight modal will appear.
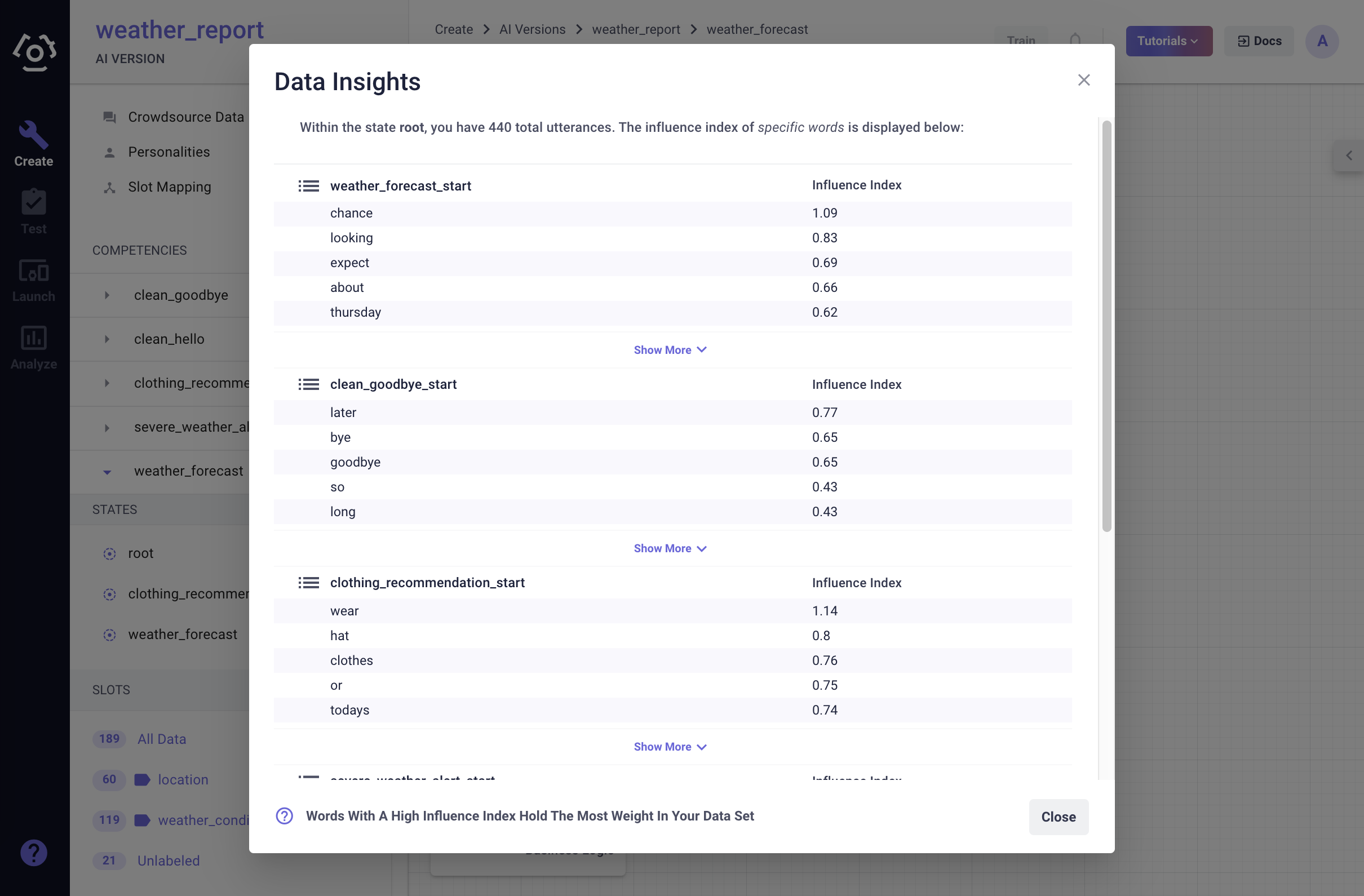
What do we do with the insights?
Make sure each of the terms listed under each intent make sense to belong under that intent. What is important to keep in mind is that each term listed will make any utterance containing that token have a higher likelihood of classifying into that intent. In our example above, the high influence index of the word "expect" should raise a red flag. If I put in a query "What should I expect to wear today?" It's likely to be classified into
weather_forecast_startwhileclothing_recommendation_startis the correct one.Another thing to look for when looking at the data insights, is stop words and punctuation that don’t have anything to do with the subject of the intent. Examples of these terms are: “is”, “are”, “the”, and any sort of punctuation. When these appear, it can be useful to try typing in utterances that could be ambiguous without the specified term into the query side bar and check the intent probability to see how much of an impact that term is making.
Note: At least two outgoing transitions are required from each state for this tool to function. As it is not possible to draw inferences about intents when there is less than two outgoing intents.
# How to utilize query classifier?
Watch this video on Query classifier vs. SVP (opens new window) to learn how to utilize query classifier and slot-value pairing.
# Best Practice Tips
- How to frame crowdsource job to collect data more efficiently
The job description should be concise yet detailed at the same time. The user shouldn't assume that the crowd has any existing knowledge pertaining to the competency/task. One effective way to describe the job is to describe a scenario that a user may be in when they need to use this assistant and ask the crowd to provide what type of questions they would usually ask. For example for balance, a good job description can be like the following:
- Imagine there is a virtual assistant that has access to a user's bank information and can answer questions about their personal finance, if that user is wondering about their bank account balance, what would they say to the assistant?
Provide multiple example utterances, for both classification and slots. The examples should be as diverse as possible, which lead to more diverse results collected from the crowd. For example, example 1:"what's my balance", example 2: "how much money do I have" is a much better example list than example 1: "what's my balance" and example 2: "what's my balance last week?"
The user should resolve common trends in their answers. Large crowdsource jobs often have similar responses and do not have enough diversity to support the virtual assistant. Try adding diversity by running several smaller crowdsource jobs with nuanced prompts and examples.
- What makes data “good”
- Good data can be thought of as a representation of how users interact with the AI. Quality and consistency are important for a good dataset. A high quality dataset requires that its utterances be correctly labelled and added to the proper use case. Consistency is also important and requires that the utterances and words/phrases in the dataset are labelled with the same ruleset and heuristics across the entire dataset.
- What amount is "enough"
- Generally we recommend to have 300-500 utterances for each classification intent label and 600-1000 utterances for each SVP slot for a human-in-the-room level of quality. However, depending on the use case, the number needed can vary. The amount of data required depends heavily on a range of factors, including the complexity of the competency, the diversity of the utterance for the competency, and the other competencies that co-exist in the same AI version (e.g. how close they are to the new competency). Therefore, there is no golden rule for how many utterances are needed for a competency. Secondly, data collection and curation is an ongoing process, even well beyond the point of the competency prototype. These numbers are minimum amount of utterances needed for a "working" competency prototype with an average complexity. Continuous testing and data curation are required to improve the competency quality. It is through testing out the competency that the user can truly evaluate whether there is enough data.
Last updates: 02/10/2020