# Slot Mapping
# What
# What is slot mapping?
Slot mapping is the process of mapping an identified slot value (word/phrase being extracted from the user query, also called raw SVP value) to a set of secondary clusters (word/phrase) through a mapper type. If it finds a good match then the raw value will be mapped to the destination value and can be used in business logic or responses.
This feature helps computers interpret messy human language better. For example, when end users are ordering french fries, they may not remember the exact name that a specific restaurant uses. Whether the users say French fries, fries, or potato strips, slot mapping can map it to french fries and place the right order. This can also be used to build resiliency against spelling errors and typos.
# What are the slot mapper types?
Shown below are the different slot mapper types available in the platform:
Semantic Comparison:
- Phrase Embedder
- Contextual Phrase Embedder
Word Comparison:
- Exact Match
- Fuzzy Match
- Simple Ratio
- Partial Ratio
- Token Sort Ratio
- Token Set Ratio
- Trie
- Character Trie
- Token Trie
- Constant Match
- Regex
- Identity
Read in the How section about How does each mapper type work and when you might use them.
# What is composite slot mappers?
Each of the eleven types of slot mappers can be applied independently as well as in combination with other mappers. There are two scenarios: first match and sequence mapper.
# What is first match?
This type of composite mapper allows you to leverage the strengths of various slot mapper types to pick the best result that matches. The mapping will stop at the first mapper that passes the defined threshold and return that result. This process is referred to as first match.
{
"type": "first_match",
"children": [...child slot value mappers w/o source/destinations...],
"source": "_OBJECT_",
"destination": "_OBJECT_"
}
An example can be:
{
"type": "first_match",
"children": [{
"type": "phrase_embedder",
"values": { "large": ["large", "big"] }
},
{
"type": "fuzzy",
"algorithm": "simple_ratio",
"values": { "large": ["large", "big"] }
}],
"source": "_OBJECT_",
"destination": "_OBJECT_"
}
# What is sequence mapper?
The sequence mapper sequentially applies slot mappers as a pipeline (i.e. the input to slot mapper i is the output of slot mapper i-1 and the output of slot mapper i is then processed by slot mapper i+1). This slot mapper allows the user to do preprocessing (see below for preprocessor types) before passing the slot values to the following slot mappers. For example, the user may decide to remove common words from the slot value before applying the slot value to a phrase embedder.
{
"type": "sequence",
"children": [...]
}
As an example, one may want to look for numbers and remove commas with the sequence mapper below:
{
"type": "sequence",
"children": [{
"type": "regex_group",
"pattern": "([0-9]+)",
"source": "_ORDER_COUNT_",
"destination": "_ORDER_COUNT_NUM_"
},
{
"type": "regex_replace",
"pattern": ",",
"sub": "",
"source": "_ORDER_COUNT_NUM_",
"destination": "_ORDER_COUNT_NUM_CLEAN_"
}]
}
# What are preprocessors?
Preprocessors are applied before major slot mappers in sequential mapping.
The Platform currently provides the following preprocessors:
- lemmatize: This preprocessor take the slot values and finds its lemma, the base form of the word. For instance:
am, are, is ⟶ be
car, cars, car's, cars' ⟶ car - lower: This preprocessor converts the slot values into lower case.
- singularize: This preprocessor converts the slot values from plural form to singular.
- regex group: This preprocessor allows you to extract only certain characters in a regex match instead of the whole thing. For example, if you had a money amount slot, you might use one regex group slot mapper to pick up the numeric amount (e.g., without a currency). This would look like
([0-9]+). - regex replace: This preprocessor allows you to remove certain characters that you do not want from a slot. For example, if you wanted to do fuzzy matching on an account slot, you might want to remove the words "account", since they're generic and will cause the fuzzy matcher to give the slot value a lower/higher score than it should.
# How
How does each mapper type work and when to use them?
How to adjust mapper threshold?
How to assign a slot mapper to slots?
How to edit/delete a slot mapper?
How to import/export a slot mapper?
# How does each mapper type work and when to use them?
| Mapper type | How it Works | When to Use | Example |
|---|---|---|---|
| Phrase Embedder | This mapper type gives higher scores to a secondary cluster value the more similar it is to the raw SVP value's semantics. The semantics for each value is derived from a pre-trained model that looks at sentence structures to learn such semantics. | Phrase embedder is used when the raw SVP value are not similar in character composition with the secondary cluster but are semantically close. | When you are building a competency that enables users to query about domestic withdrawal limit. You might create a slot mapping for location slot of which the second cluster includes domestic, local, within the country, U.S.A., United States to name a few. |
| Contextual Phrase Embedder | Works similarly to a phrase embedder in that it assigns a similarity score to each secondary cluster. However, the scoring is dependent on surrounding words or context. | Similar to but more powerful than a phrase embedder, this mapper should be used when the secondary clusters are phrases or sentences. | When a competency may have utterances with slots that change their meaning based on the surrounding words. Check How to make use of contextual phrase embedder for more details. |
| Exact Match | The raw SVP value will be mapped to a value in the second cluster if they are an exact match. | Exact match might not be the one that's used the most frequently, but it is useful when you need something to be strictly mapped otherwise it can cause undesirable consequences . | When you are building a competency that enables users to transfer money from their account to another. You probably want to make sure that the slot mapper type for both source account and destination account matches exactly to the values provided in the second cluster. |
| Simple Ratio | The raw SVP value and secondary clusters are compared using a Levensthein distance. A score is assigned based on the number of edits required to make the raw SVP value equal to the secondary cluster, an exact match is a score of 1.0. | Simple ratio works well when the raw SVP value and secondary clusters are short, 1-2 words in length, and similar in length. | As long as the raw SVP value and the second cluster values are relatively short, simple ratio can do a good job at mapping the value. The same example for phrase embedding is applicable for simple ratio too. |
| Partial Ratio | The raw SVP value and secondary cluster are first compared based on their length. If the shorter string is length m, and the longer string is length n, we’re basically interested in the score of the best matching length-m substring. | Partial ratio works well when the raw SVP value and secondary cluster being compared are not consistent in length and word order does not matter. | Imagine you are building a competency that enables users to book baseball tickets. For baseball team names like "Yankees", "New York Yankees" and "New York Mets", if using simple ratio "New York Yankees" would be more likely to be mapped to "New York Mets" but these are two different teams. So here a better heuristic is partial ratio, with which "New York Yankees" would get a perfect score with "Yankees". |
| Token Sort Ratio | The raw SVP value and secondary clusters are compared by first tokenizing these values, sorting them alphabetically, then performing a simple ratio comparison. | Token sort ratio works well when the raw SVP value and second cluster value being compared are similar in length and word order matters. | With the same ticket booking example, if users' query comes in as "Detroit Tigers vs. New York Mets" while seller lists the game as "New York Mets vs. Detroit Tigers", that would completely throw simple ratio and partial ratio off. Token sort ratio would sort the value alphabetically first, detroit tigers vs new york mets --> detroit mets new tigers vs york, which nicely solves the ordering problem. |
| Token Set Ratio | The raw SVP value and secondary clusters are tokenized and grouped. The groupings consist of an intersection group, overlapping token that appears in both the raw SVP value and the secondary cluster, and remainder groups for both the raw SVP value and the secondary cluster. These groups are then compared to determine similarity. To illustrate it using a formula: [SORTED_INTERSECTION] + [SORTED_REST_OF_VALUE1] gets compared against [SORTED_INTERSECTION] + [SORTED_REST_OF_VALUE2] | Token set ratio works well when word order matters and the raw SVP value and second cluster value being compared are very different in length. | With the same ticket booking example, if a user asks "book me a ticket for White sox of Chicago at Detroit Tigers" while a more formalized way is "Sox vs. Tigers". Token sort ratio is not very useful in this scenario since the first value is a lot longer than the second one. With our formula, we get: INTERSECTION --> sox tigers white, GROUP 1: sox tigers vs white, GROUP 2: at chicago detroit of sox tigers white . Then these three groups get compared. In real life, a "best match possible" approach seems to provide the best outcomes so GROUP 1 and GROUP 2 get a pretty high score. Although the down side of token set ratio is that duplicate tokens get lost in transformation. |
| Character Trie | A character trie searches in character level and returns candidates for a future fuzzy match. Therefore, you will need to run a fuzzy match with the return values of a character trie mapper to get the final result. | This works well if the dataset is large and the user wants to narrow down the list of potential matches. In comparison to other mappers, trie mappers can find matches among a large dataset more efficiently. | If the value the user wants to map is "bank of guam" and there are two values "bank of gum" and "bank of guam" in the trie dataset, then the character mapper would return both these values since they are similar. Then, the user would run a fuzzy match for the two candidates against the value "bank of guam" in which the data "bank of guam" would be the strongest match since it is an exact match. |
| Token Trie | A token trie first tokenizes the string and searches for matches. It can be thought of as a prefix matcher. | This mapper should be used when the utterance is an exact match. This could be compared to exact mappers but is more efficient when searching in a large dataset. | If the user wants to match the value "bank of", this mapper would return all results that start with "bank of". |
| Constant | This mapper type allows you to add a catch-all value at the end of the end of a mapper. | This is mapper type is used at the end of the mapper when no match is found. Without adding it, no destination slot will present in the Slot Values dictionary. | If you wish to know that the slot mapper didn't find a match for the raw SVP value, you could add a constant match at the end of the mapper so that you are alerted. The default mapped value is "NULL". |
| Regex | The regex slot mapper allows the user to match slot values based on a regular expression. | This mapper is useful when the secondary cluster values follow a certain pattern. For example, validating things like phone number or email addresses. | |
| Identity | The identity slot mapper returns the input slot value. | Similar to constant mapper, this mapper is useful when you want unmapped slots to be retained. |
# How to create a slot mapper?
To access the slot mapping page,
- (Suppose you are in the Create tab inside an AI version) select Slot Mapping in the competency sidebar.
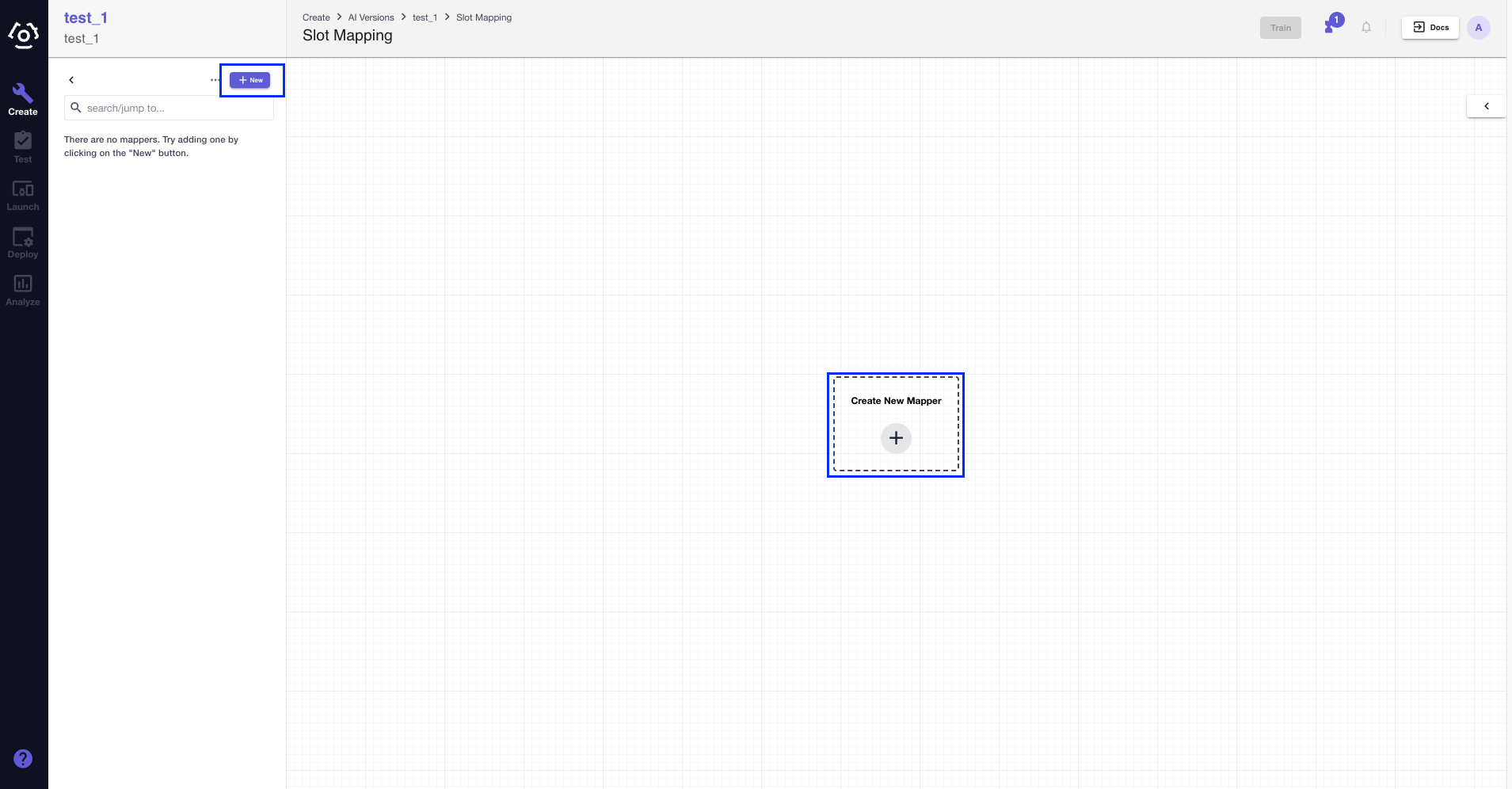
On the slot mapper canvas, choose Create New Mapper to create a slot mapper. Or click + New in the sidebar.
In the modal popped up, give the mapper a name.
Note: Slot mapping in the platform is global which means one slot mapper can be applied to multiple slots across competencies. It is wise that you give the mapper a name that is relatively general. Keep reading to learn How to assign a slot mapper to slots?
Now that we have a slot mapper, we need to add preprocessors or configure mapper type or both to it depending on your design.
- Click
 and choose a mapper type in the dropdown menu.
and choose a mapper type in the dropdown menu.
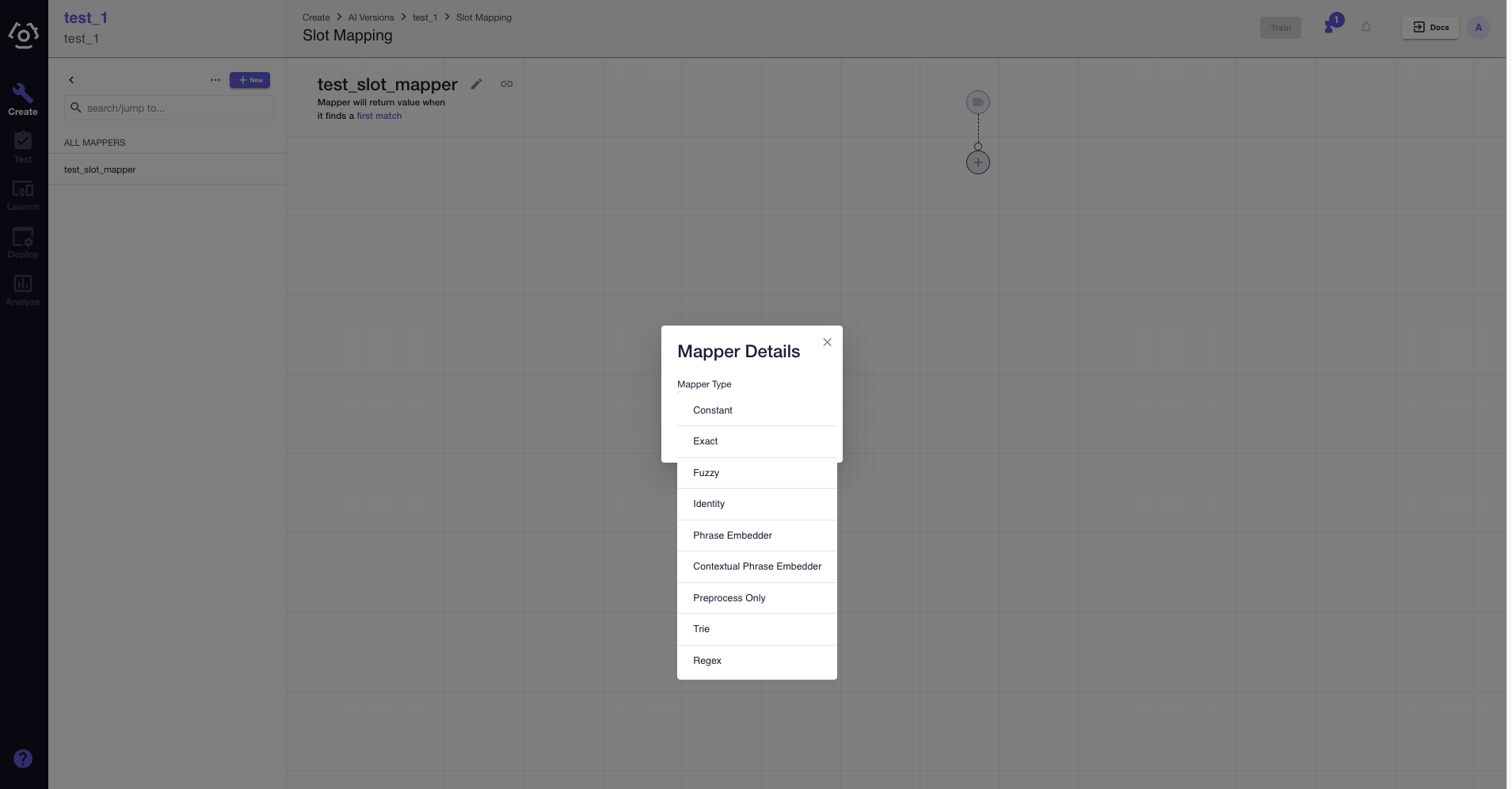
- After a mapper type is selected, the slot mapper detail sidebar reveals. Here, you can add preprocessors, configure the algorithm type (applies to fuzzy match), mapped value and secondary clusters. However, preprocessors are not available in contextual phrase embedder.
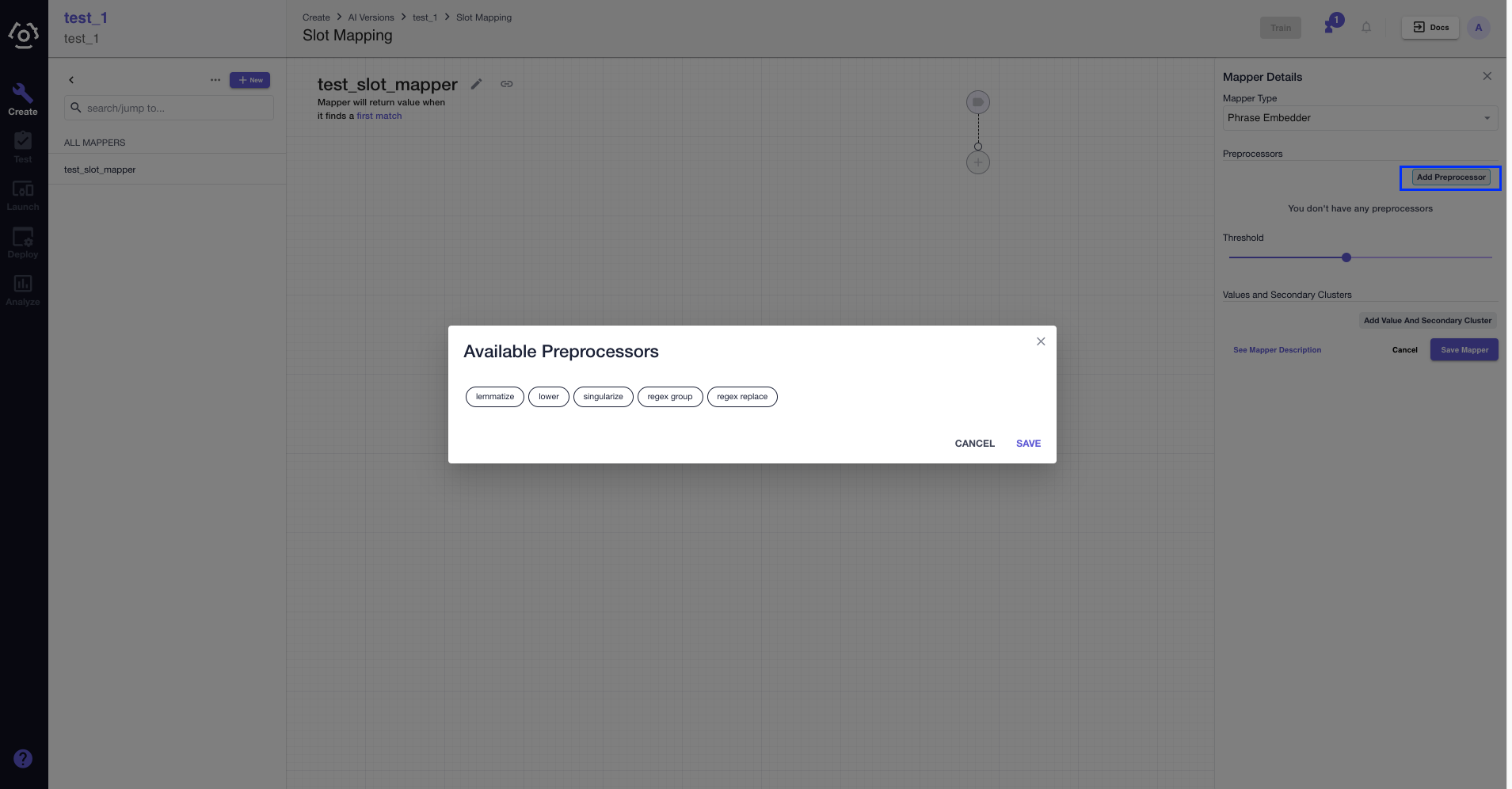
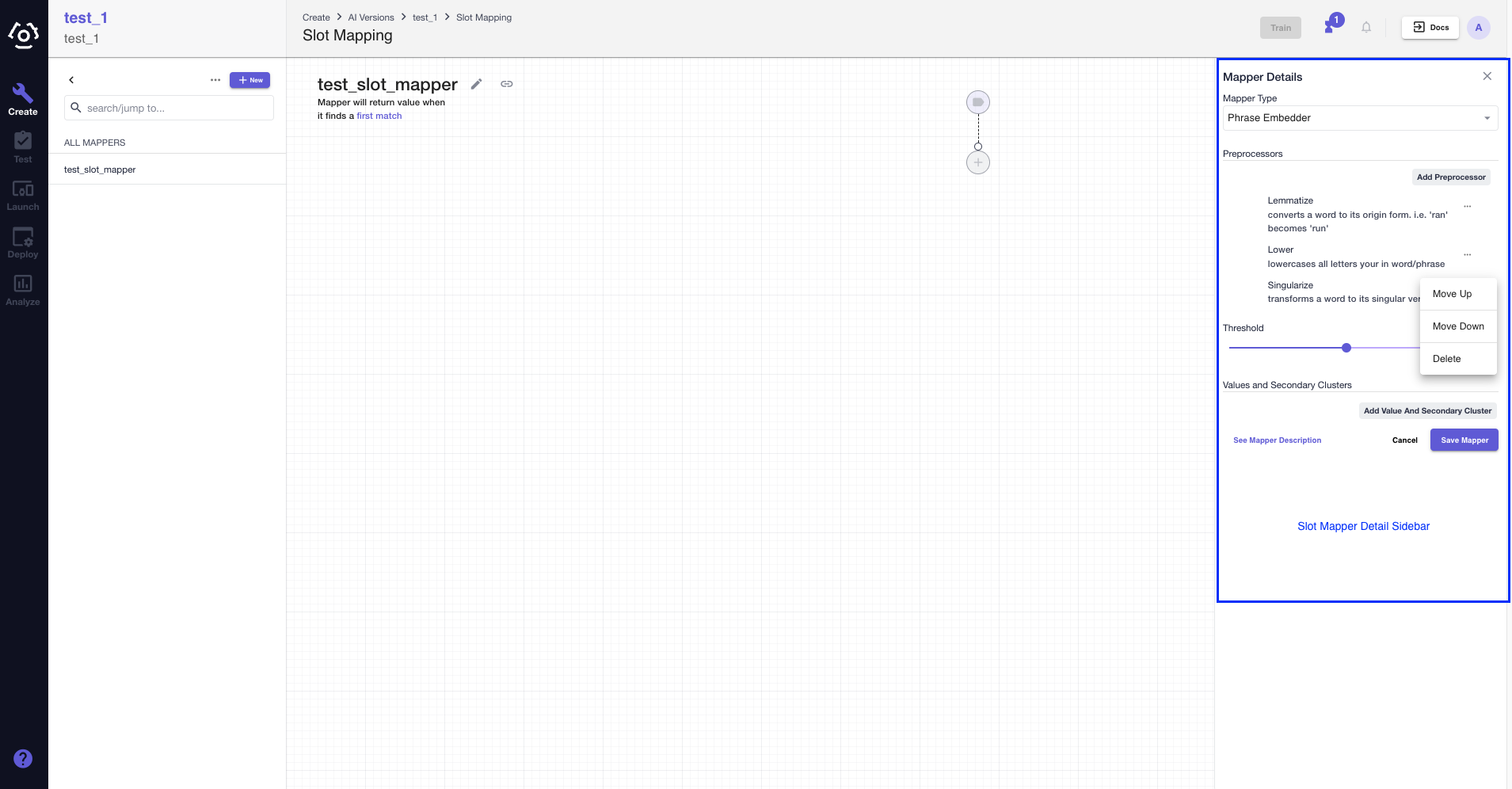
If you have multiple preprocessors, you can adjust their sequence too.
Note: You can adjust the threshold for phrase embedder, contextual phrase embedder, and fuzzy match, reference How to adjust mapper threshold? to learn what the threshold mean and how to adjust it.
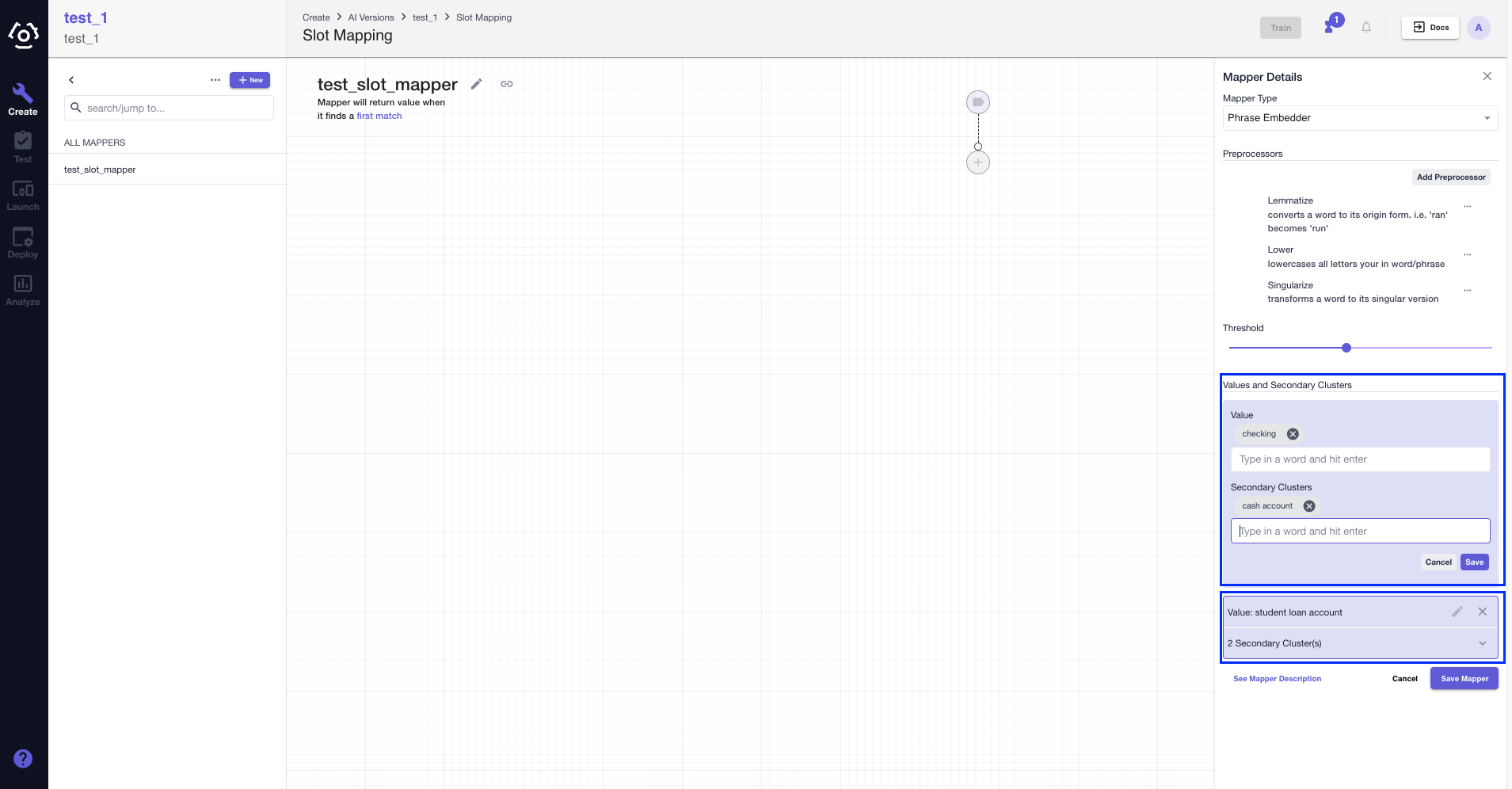
Add value in the Value and Secondary clusters fields, press enter after entering each value. You should see them change to chips and then click Add Value and Secondary Cluster.
If everything looks good, click Save Mapper.
In the block created, you can view the details of the secondary cluster, edit the values and delete the block.
# How to adjust mapper threshold?
Threshold for phrase embedder and fuzzy match are adjustable. The default value for threshold is 0.45.
Since phrase embedders work based on semantic meaning, if the threshold is too high (close to 1.0), you might miss words that are semantically similar. Conversely, if the threshold is too low (close to 0.0), even if two words are very different, they might still be matched.
For fuzzy match, same principle applies. If the threshold is too high (close to 1.0), it will to equal to an exact match. If the threshold is too low (close to 0.0), even the Levensthein distance is far, the raw SVP value still can be mapped.
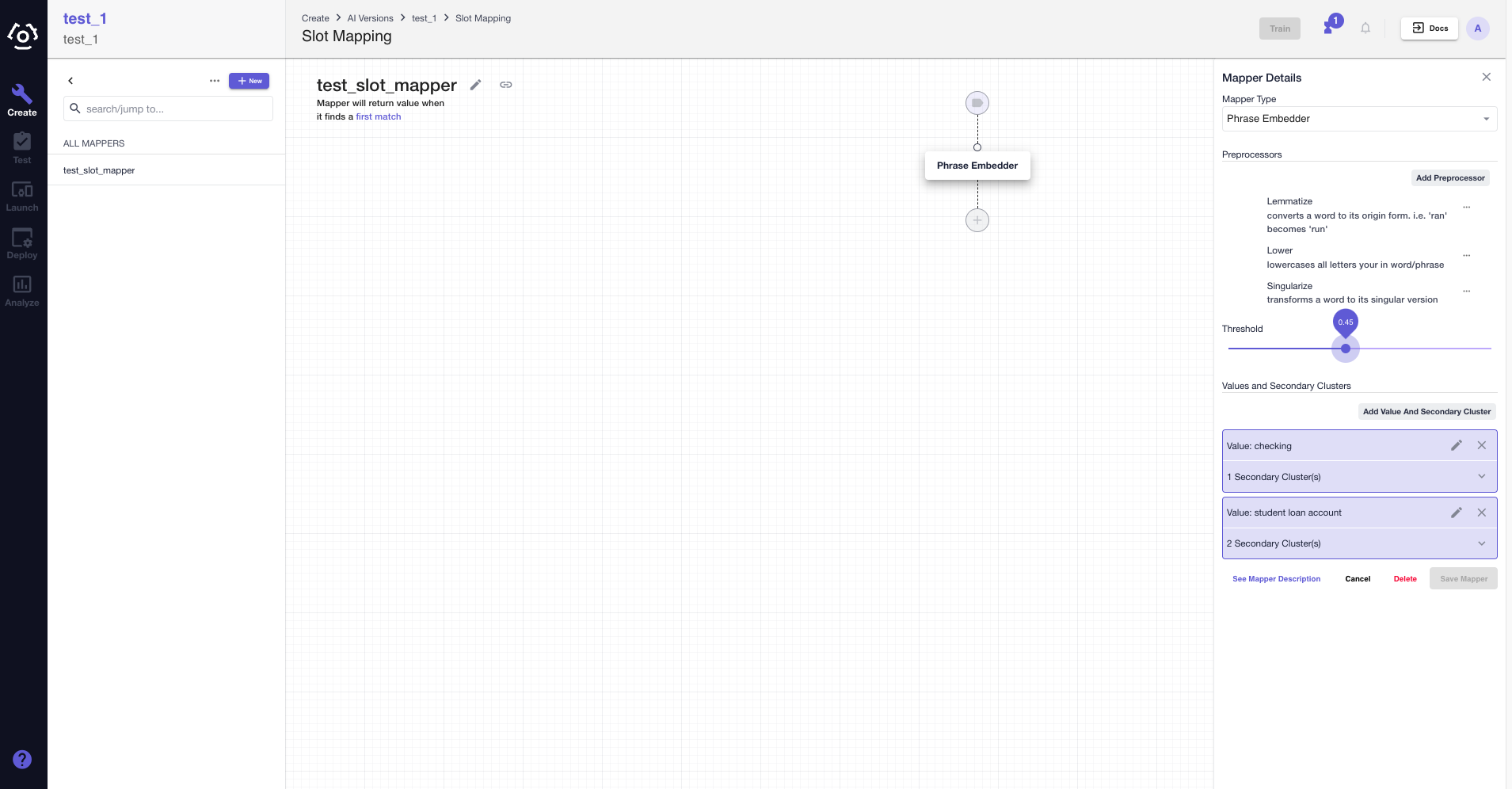
To adjust the threshold:
- Choose the mapper type on the slot mapper canvas. In the slot mapper detail sidebar, you will see a threshold bar.
- Click on the dot, you will see the default value is set to 0.45. You can slide it left and right to adjust the value as you see fit.
- Don't forget to Save Mapper.
# How to assign a slot mapper to slots?
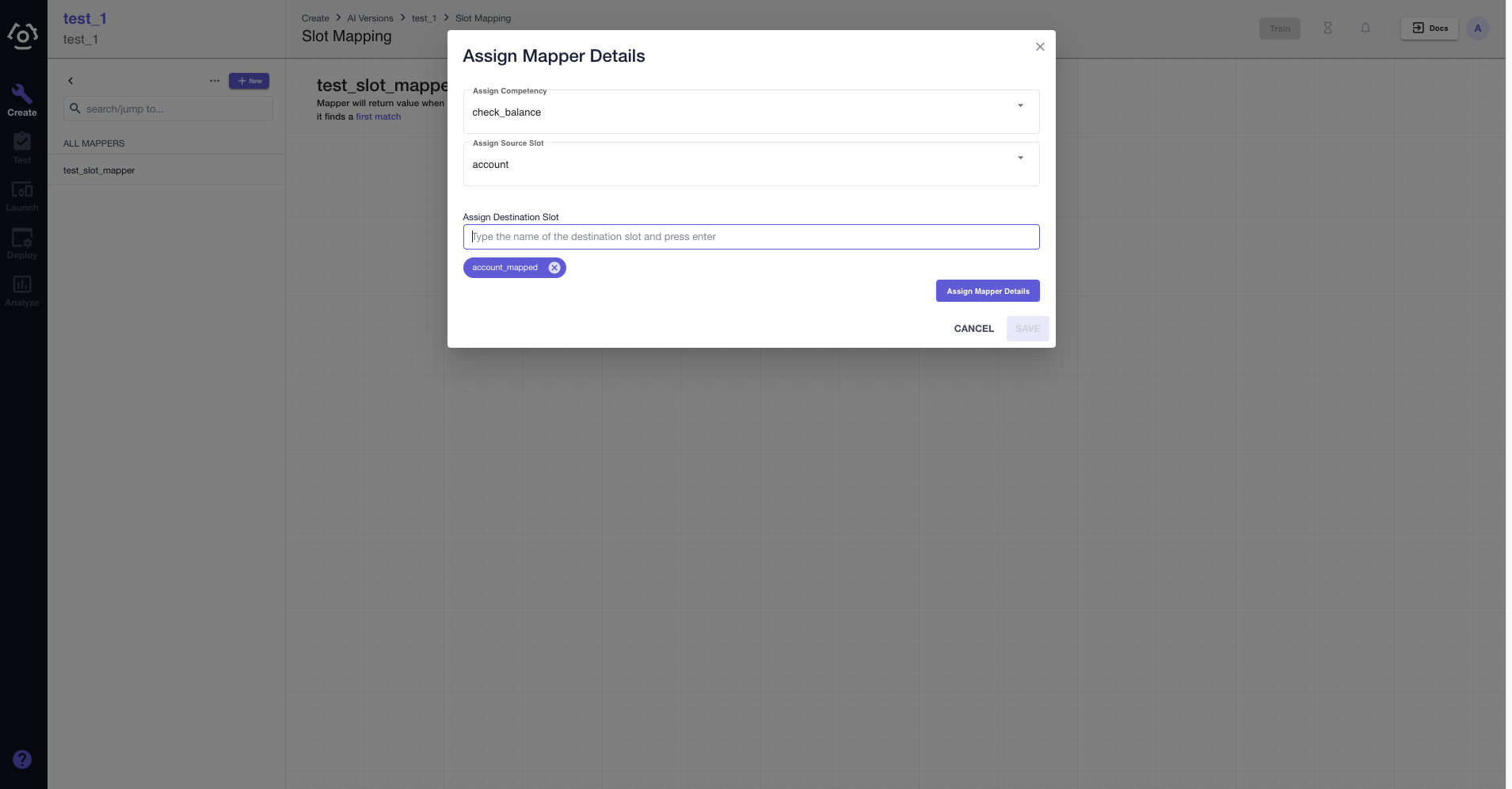
We have mentioned earlier that slot mappers are global in the platform. They can be assigned to different slots across competencies which help save time recreating them. When your slot mapper is ready to be assigned, click  .
.
In the Assign Mapper Details modal popped up, select the competency and slot to which you are assigning the slot mapper from the dropdown menus.
Give the destination slot a name. It should be different from the source slot name and other slots to which you are assigning this mapper. (You don't have to memorize it, an error message will gently remind you.)
Click Assign Mapper Details to assign.
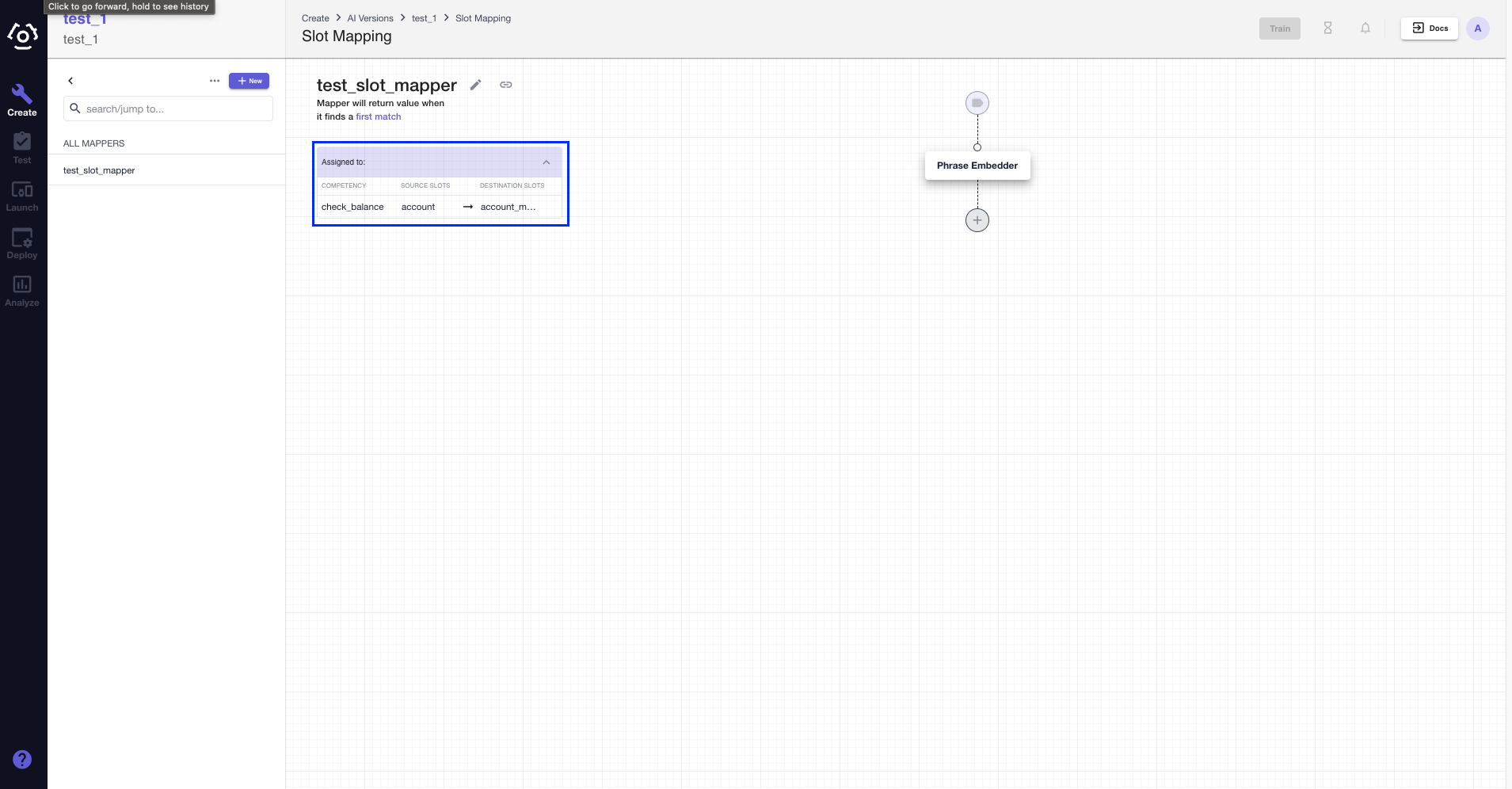
Once you have assign the mapper to all the slots of your choice, be sure to Save.
Now you should be able to see the mapper assignment details in the assignment table.
- Contextual Phrase Embedder allows you to highlight certain keywords within the secondary clusters. To highlight a single word or a continuous group of words, just select the word(s) and click keyword in the pop-up window as shown below.
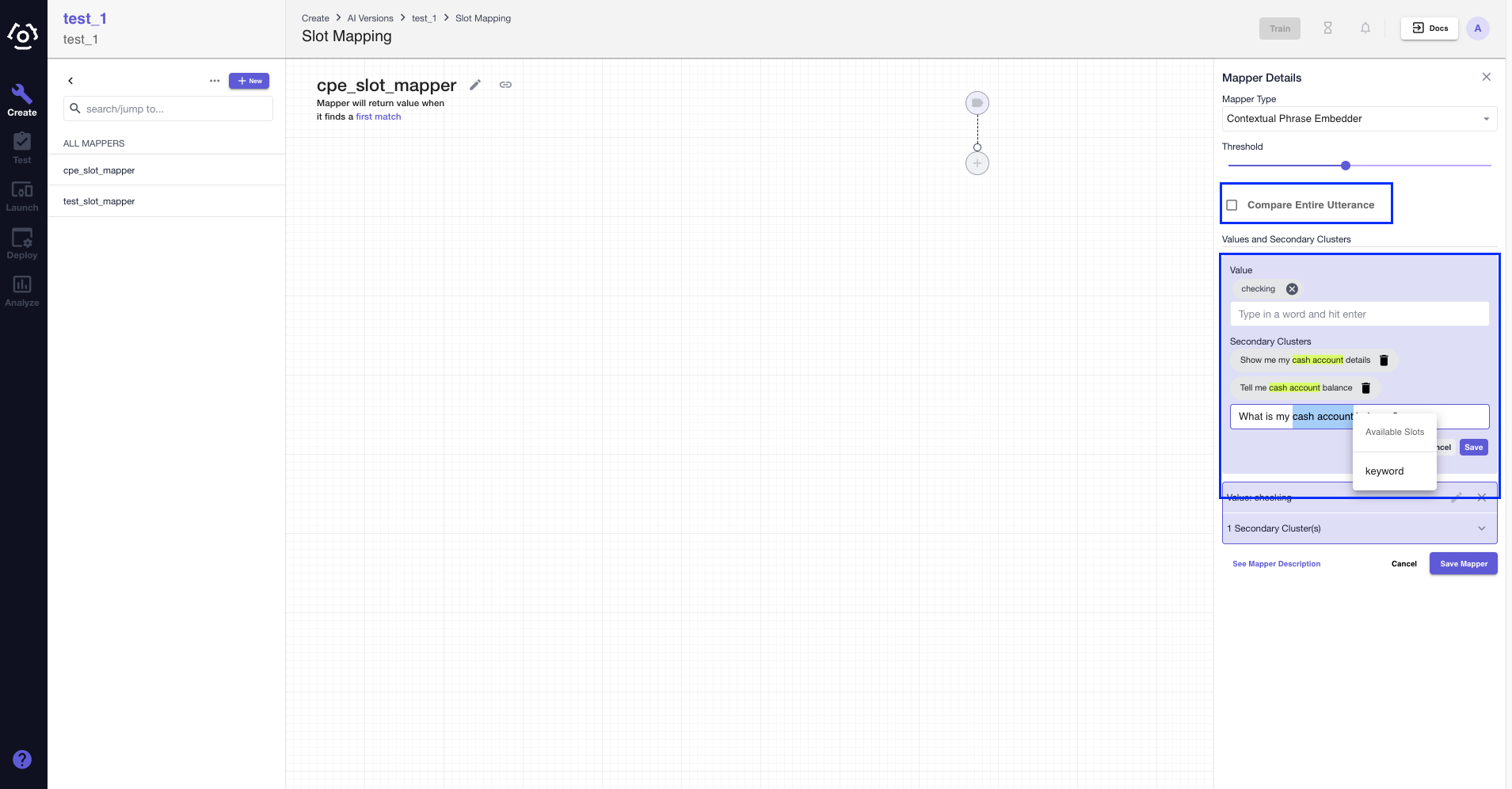
# How to edit/delete a slot mapper?
To delete a mapper:
In the slot mapper sidebar, click the overflow menu
 . The Delete option will show up in the menu.
. The Delete option will show up in the menu.Deleting a mapper will break the links between the mapper and all the slots. If you wish to remove certain links:
Go to the Assign Mapper Details modal and select
 at the end of the associated row.
at the end of the associated row.To edit the mapper name:
Click
 next to the mapper name. After you make changes, press enter.
next to the mapper name. After you make changes, press enter.To edit mapper types, mapped value and secondary clusters:
Click the mapper type name in , mapper details sidebar should appear. Edit the mapper block to make changes mapper types, mapped value and secondary clusters.
# How to import/export a slot mapper?
To import a mapper:
On the slot mapper page, click the the overflow menu
next to + New, you will find the Import option. Select or drag and drop the .json file that contains the mapper.To export a mapper:
Hover over the mapper, in the overflow menu
you can delete or export the mapper. Once you select export, your mapper will be exported as a JSON file.
# How to make use of Contextual Phrase Embedder?
Under the hood, the Contextual Phrase Embedder (CPE) is powered by a pre-trained transformer based model. As such it understands texts and finds similarities between them without any additional training. We will explore a use case where the CPE works particularly well and follow up with a set of recommended hyper parameters.
Consider a competency called show transactions which shows transactions made by a customer at a place of interest, which can be a merchant (store), a location (city), or both. We will use the CPE to disambiguate the place of interest, identifying it as either a merchant or location.
First off, let us look at the configuration of the CPE slot mapper below. There are two mapped values location and merchant - each with its own secondary clusters. Notice how the keywords within the secondary clusters are appropriately highlighted. This slot mapper has been assigned to the place_of_interest slot, so that as soon as the SVP identifies the slot, the CPE mapper is triggered.
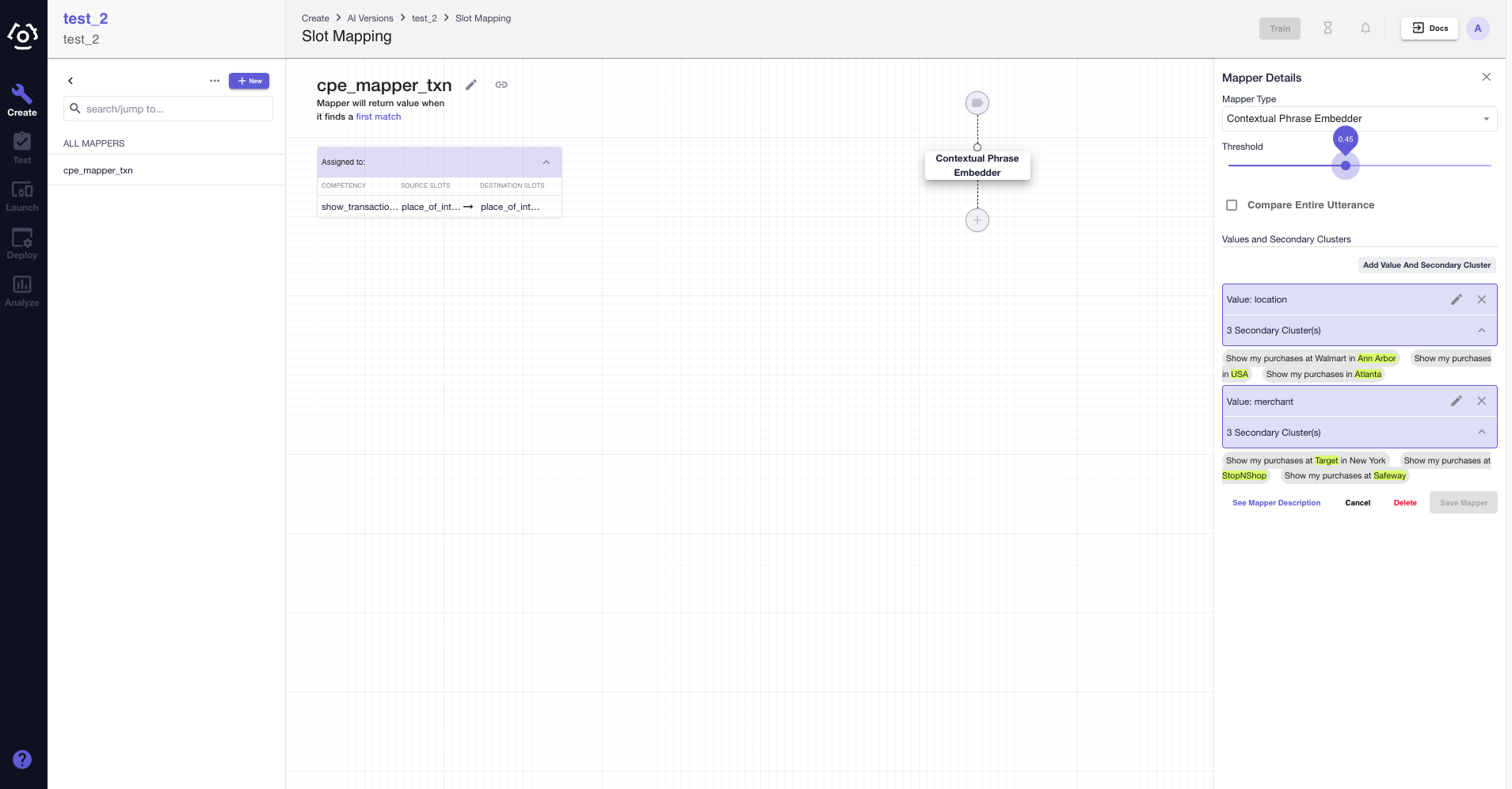
Let us run a few sample utterances to see it in action.
Utterance #1: What about my purchases at Macys
Intent and Slot Values: It is a relatively simple utterance and CPE is able to map the slot value Macys to merchant. See below.

Utterance #2: What about my purchases in Boston
Intent and Slot Values: Again, a relatively simple utterance as CPE is able to map the slot value New York to location. See below.

Utterance: What about my purchases at Macys in Boston
Intent and Slot Values: Here the utterance has two place_of_interest slots - Macys and Boston. The CPE acted upon each and mapped them correctly to merchant and location respectively.

In general here are recommendations about the parameters to get the best out of a CPE slot mapper based on empirical observations.
# Threshold
It determines the threshold of the similarity score beyond which two texts are considered similar. We do not recommend setting the threshold too high, as it may result in False Negatives (misses). The CPE, by design, returns the best match, which is the secondary cluster with the highest similarity score with the slot value. As such setting the threshold between 0.4 and 0.5 seems optimal.
# Compare Entire Utterance
It is a boolean flag defaulted to No. By enabling it, the entire utterance is compared rather than just the slot value. It may be intuitive to enable it for better context, but the CPE does not encode words in isolation. In other words, the word checking in the following texts: Show my checking balance and I am checking my savings balance will have different representations as the context is different in each. As such, we recommend disabling it for most use cases.
However, for use cases that involve mapping a personal property such as account name, something that does not carry any meaning without surrounding words, we have seen that comparing entire utterances yields better match with secondary clusters. One such example of an utterance is Show my transactions on my mickey account in Boston. Here the account name is mickey, and when it is compared to secondary clusters such as Show purchases on abcd account in New York, it yields a better match with compare utterance enabled.
# Value and Secondary Clusters
Here are the recommendations for secondary clusters:
- Add phrases or full sentences, as the CPE works best with context.
- Highlight the keywords within each secondary cluster item so that the CPE knows to focus on the keywords while inferring.
- For a given value, add diverse secondary clusters that are semantically similar. On the other hand, if you add similarly structured secondary clusters with just differences in keywords, it will not be helpful. For example the secondary cluster set of
Show my transactions in New YorkandWhat about my purchases in New Yorkis recommended over the setShow my transactions in New YorkandShow my transactions in New Orleans, as the former is structurally different and hence diverse. - If entities such as city, country, place, merchants and so on need to be included in secondary clusters, then use as few unique names as possible. For example, if a city needs to be added, then pick one city and reuse it across the rest of the secondary clusters. Doing so will avoid causing accidental match with an incorrect secondary cluster when the city in the user utterance overlaps with that in the secondary cluster. We also do not recommend using in the secondary clusters popular entity names or entity names most likely to be used by end-users in their queries.
More specifically, the CPE can be used to disambiguate a merge slot. A merge slot can take on different meanings depending on its surrounding words. In the example shown above, the place_of_interest is a merge slot and CPE is used to identify it as either a location or merchant. On successful mapping, there is a one-to-one mapping between the values of the original and mapped slot, as the example above shows the original slot place_of_interest to contain macys, boston and the mapped slot place_of_interest_mapped to contain merchant,location. However, if the mapping of either were to fail, then the one-to-one mapping may cease to exist. To avoid confusion, we recommend adding after the CPE a Constant Mapper that always maps to NULL.
Lastly, as a developer, you may want to evaluate the similarity scores for different combinations of secondary clusters. If so, you can use the Contextual Phrase Embedder within BLS and set the return_score to True to access the similarity score of each secondary cluster item and curate the data accordingly. Follow the BLS 2.0 documentation under the Contextual Phrase Embedder section for details on how to use Contextual Phrase Embedder in BLS.
Last updated: 09/01/2023