# Classifier Pipelines
# What
# What is a classifier pipeline?
Classifier Pipelines enable you to configure a full classification pipeline at the state level. The classifier configurations can be broadly categorized into three categories:
- Preprocessors: apply transformation on the input text before being fed to the vectorizer or the classifier model.
- Vectorizer: converts the text to a machine readable vector format.
- Classifier Model: assigns a class to an input vector based on its supervised learning.

Refer to configuration choices to know more about the available configurations, and the factors that may influence your choice of these configurations.
# How
# How to create classifier pipelines
- You can view and create new classifier pipelines by going to a version and clicking
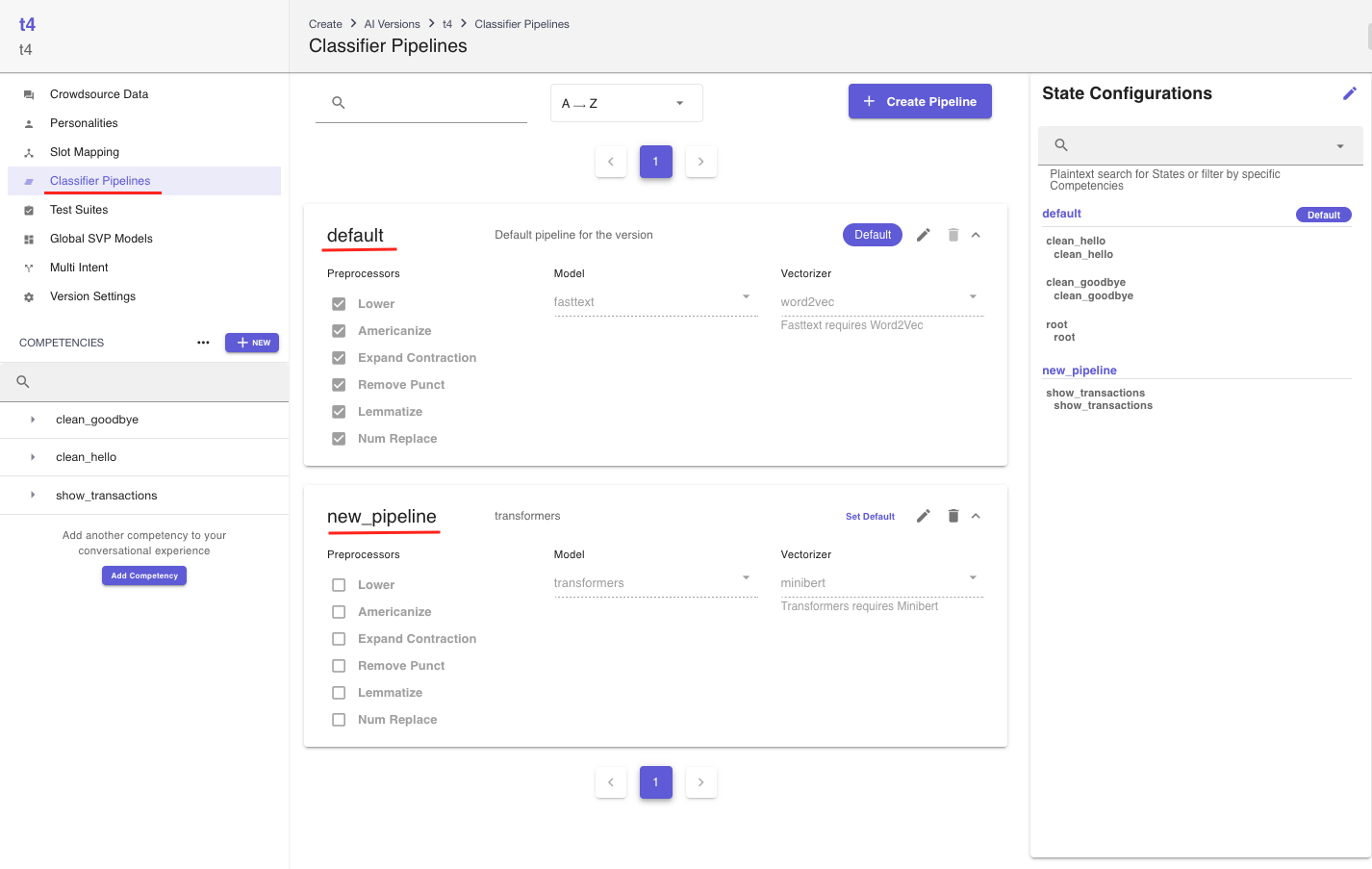
Classifier Pipelineson the version sidebar. By default, every version will have a Default pipeline with all preprocessors enabled, the model set asfasttextand the vectorizer set asword2vec. All states will be configured to this pipeline upon version creation. In the screnshot below, two pipelines nameddefaultandnew_pipelineare created, and thedefaultpipeline is the designated Default pipeline.
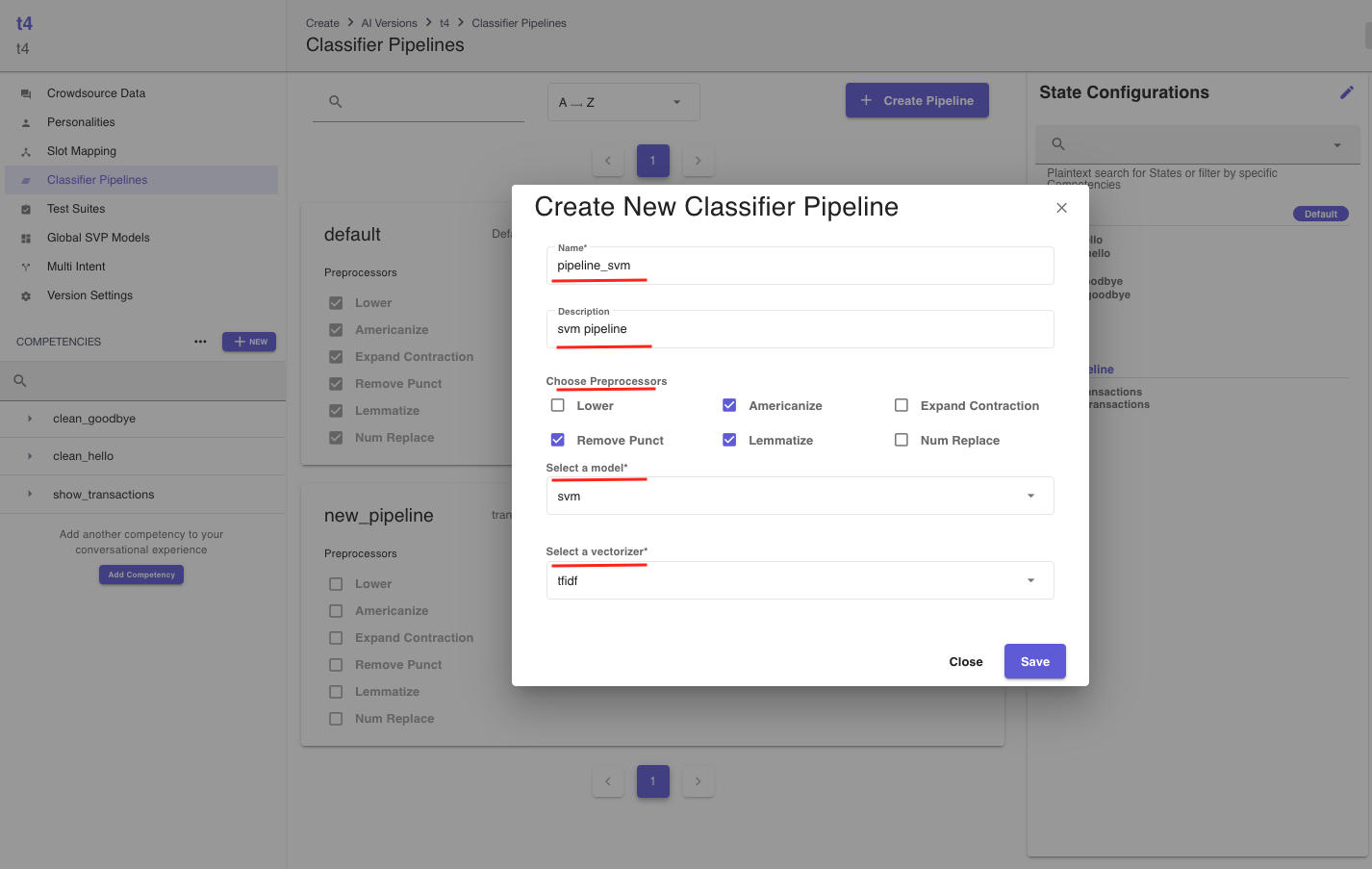
- You can create a new classifier pipeline by clicking on the
Create Pipelinebutton and filling out the required fields. While theNameandDescriptionfields are self-explanatory, you can refer to configuration choices to know more about availablePreprocessors,Models, andVectorizers. Note thatfasttextrequiresword2vecandtransformersrequiresminibert.
- There is exactly one default classifier pipeline per version. You are allowed to change the default pipeline, and if you change it, all newly created states will belong to the new default pipeline. The default pipeline cannot be deleted.
# How to assign a classifier pipeline
You can view the current list of the state-pipeline assignments through the State Configurations sidebar. You can edit the state-pipeline assignment in two ways:
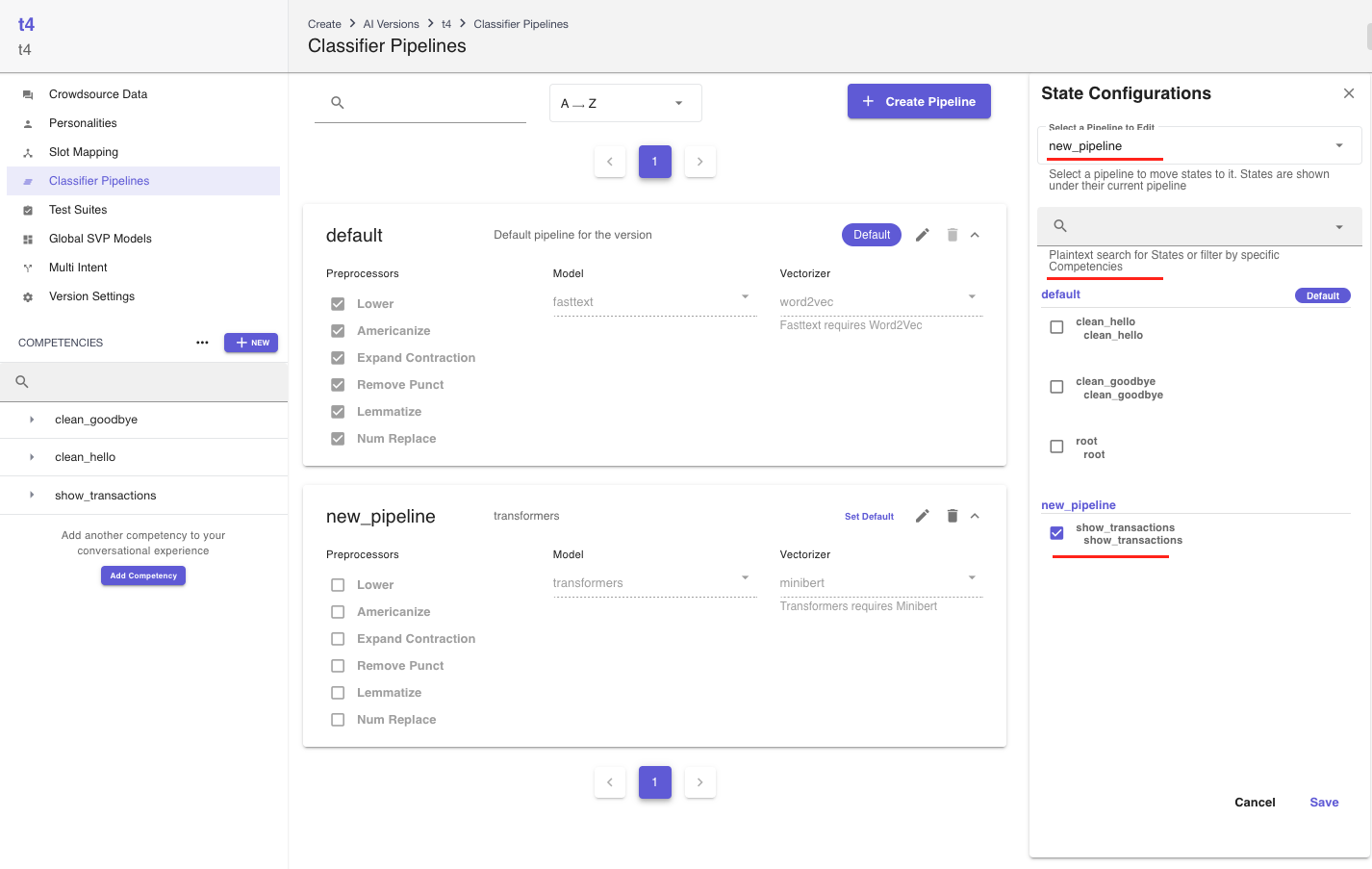
- You can edit the state-pipeline assignment by clicking the edit mode on the
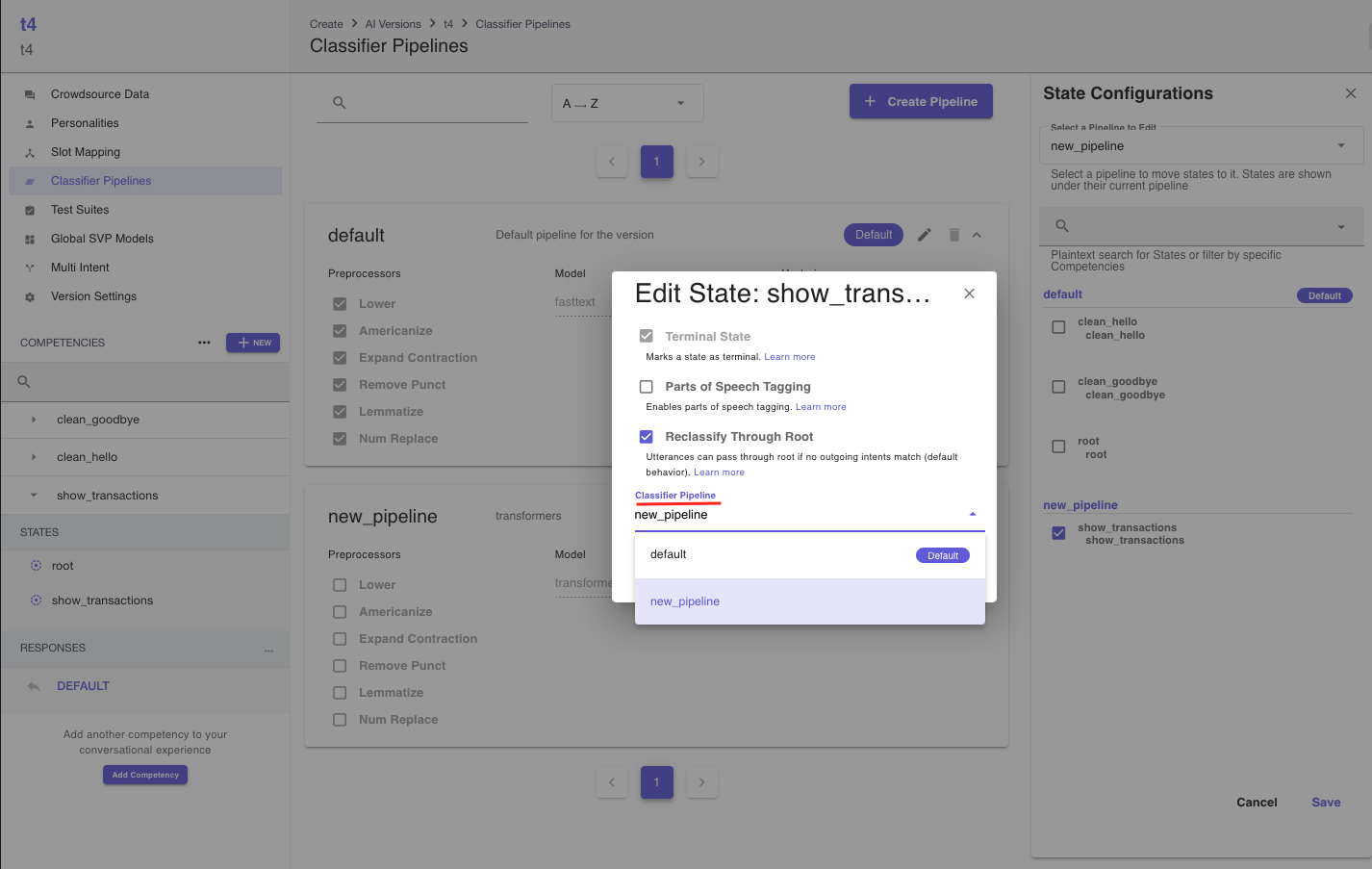
State Configurationssidebar. Note that you cannot remove any states from theDefaultpipeline. So, to assign a pipeline other thanDefaultto a state, you should select the desired pipeline using theSelect a Pipeline to Editdropdown and then assign the state to it. In the screeshot below, theshow_transactionsstate is assigned to thenew_pipeline, whereas the rest are assigned to theDefaultpipeline.
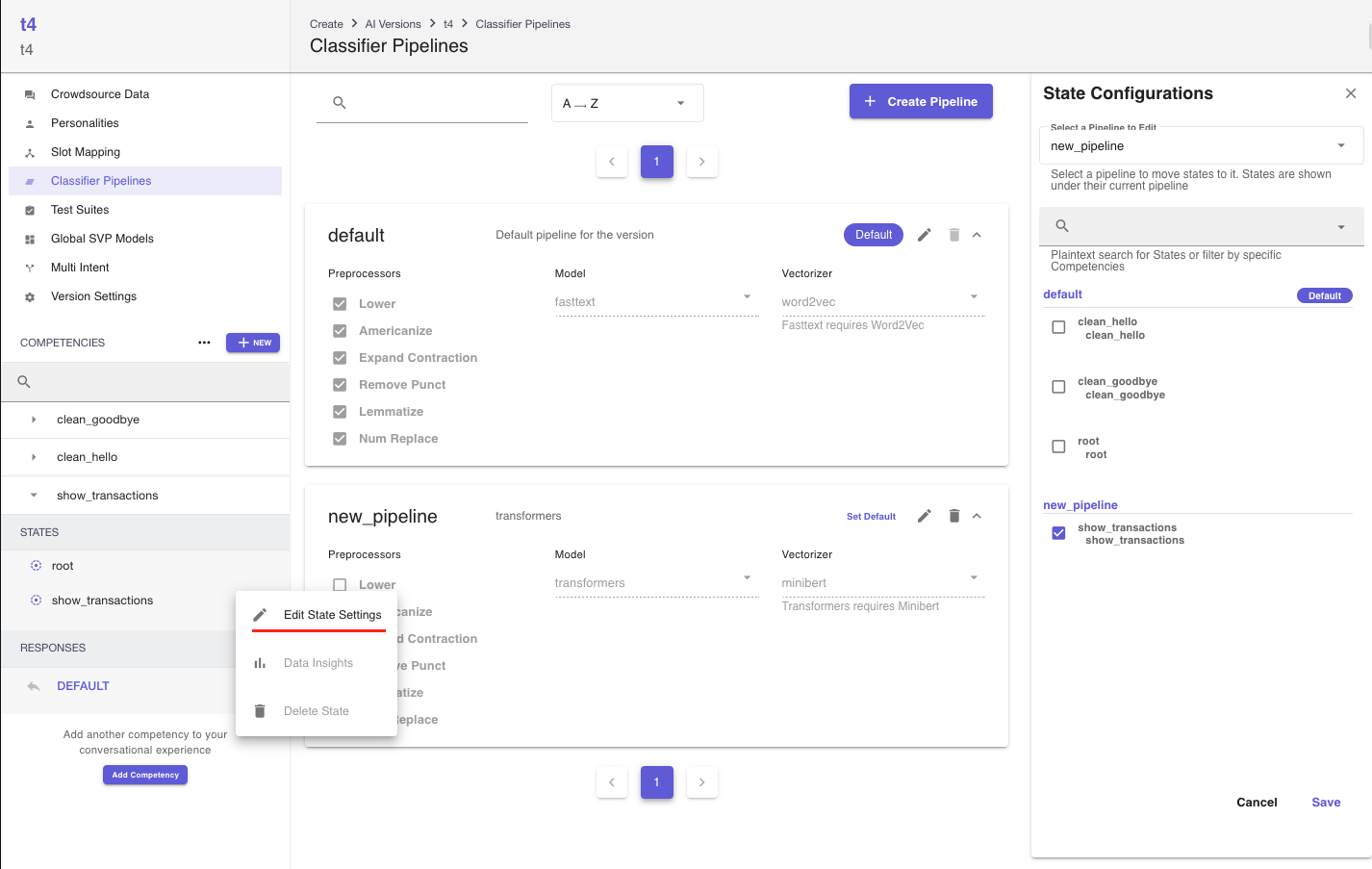
- You can also edit a specific state's classifier pipeline by using the edit state dialog as shown in the screenshots below.
# How to choose pipeline configurations
In the following sections, we will list the available preprocessors, vectorizers, and classification models.
- Preprocessors
| Name | Notes |
|---|---|
| Lower | Convert text to all lowercase |
| Americanize | Convert non-American English words to their American English equivalent |
| Expand Contraction | Replace contractions with full representations |
| Remove Punctuation | Remove Punctuation |
| Lemmatize | Remove word endings to attain base words |
| Num Replace | Replace numbers with a special token |
- Vectorizers
| Name | Family | Notes |
|---|---|---|
| One Hot | Bag of Words | Best for straightforward problems with clear class label differences. Lightweight and fast. |
| Count | Bag of Words | Similar to one hot model, but with labeling based on term frequency. Lightweight and fast. |
| TFIDF | Bag of Words | Simple model with labeling based on term frequency and inverse document frequency, best used when large amounts of unimportant words are present in the training data. Lightweight and fast. |
| Word2Vec | Word Embedding | Predictive embedding model that is pre-trained except when used with fastText (when it also utilizes subwords). Fast but will require significant memory. |
| GLoVe | Word Embedding | Pretrained vectorizer which is focused on global word co-occurrence. Fast but will require significant memory. |
| Universal Sentence Encoder | Sentence Embedding | Sentence embedder pre-trained on various NLP tasks. Fast but requires significant memory. Not recommended to be used for most use cases. |
| ELMo | Sentence Embedding | Pretrained predictive embedding model which utilizes a Bi-LSTM for training. Fast but will require significant memory. |
| Roberta | Sentence Embedding | Large fine-tuned sentence-transformer model based on RoBerta transformers. Will lead to increased train and infer time; GPU recommended. |
| Minibert | Sentence Embedding | Small fine-tuned sentence-transformer model based on BERT transformers. Smaller than its Roberta counterpart, with comparable performance. Most preferred among the Word/Sentence embedding class of vectorizers. GPU recommended. |
- Classifer Models
| Name | Training Speed | Inference Speed | Scalability | Supports Pretraining | Performance | Notes |
|---|---|---|---|---|---|---|
| fastText | Excellent | Excellent | Excellent | False | Good | An excellent fast model that can scale to be trained on huge amounts of data. It is best used with large datasets or when speed is paramount. Beware that it performs poorly on few-shot training data. |
| Logistic Regression | Excellent | Excellent | Good | True | Good | A simple linear model useful for getting a baseline performance. It is the quickest model outside of fastText and can be especially useful for getting a quick idea of the performance of vectorizers on a particular problem. |
| Support Vector Machine | Good | Excellent | Good | True | Good | An excellent all-around model, the SVM is most useful on high-dimensionality datasets with a clear label distinction. This makes it especially effective when paired with one hot, count, or tfidf vectorizer |
| Multi-Layer Perceptron | Good | Good | Good | True | Good | An excellent all-around model, the MLP is useful on most datasets. It is capable of fitting more complex problems where there is not as clear of a distinction between classes |
| Gradient Boosted Decision Tree | Poor | Poor | Poor | True | Poor | The gradient-boosted decision tree has overall poor performance on most datasets. It is particularly difficult to generalize. It will benefit most from automatic hyper-parameter optimization (a feature not available yet). |
| Transformers | Poor | Poor | Excellent | True | Excellent | These models can perform excellently on the most complex problems and scale well to even the largest datasets. They tend to be slower at inference and training than most other models. GPU highly recommended |